Python: 3.13.0 (v3.13.0:60403a5409f, Oct 7 2024, 00:37:40) [Clang 15.0.0 (clang-1500.3.9.4)]
Platform: macOS-26.3.1-arm64-arm-64bit-Mach-O
NumPy: 2.2.3
CPUs available: 8JSC 370: Data Science II
Week 10: High Performance Computing
What is HPC
High Performance Computing (HPC) can relate to any of the following:
- Parallel computing — using multiple resources (threads, cores, nodes, etc.) simultaneously to complete a task faster.
- Big data — working with large datasets (in/out-of-memory), e.g. via lazy loading and chunked processing.
- Accelerated computing — offloading work to specialized hardware such as Field Programmable Gate Arrays (FPGAs) and Graphics Processing Units (GPUs).
Note
Today we will focus on parallel computing.
Serial computation

Here we are using a single core. The function is applied one element at a time, leaving the other 3 cores without usage.
Serial computation
- Serial programming is the default method of code execution.
- Code is run sequentially, meaning only one instruction is processed at a time (line-by-line).
- Code is executed on a single processor, so only one instruction can execute at a time.
Parallel computation

Here we are taking full advantage of our computer by using all 4 cores at the same time. This will translate in a reduced computation time which, in the case of complicated/long calculations, can be an important speed gain.
Parallel computation
Parallel computing is the simultaneous use of multiple compute resources to solve a computational problem:
- A problem is broken into discrete parts that can be solved concurrently
- Each part is further broken down to a series of instructions
- Instructions from each part execute simultaneously on different processors
- An overall control/coordination mechanism is employed
Parallel computation
The parallel compute resources are typically:
Shared memory (single node) — a single computer with multiple processors/cores that all share the same RAM. Fast communication between cores, but limited by the number of cores and memory on one machine.
Distributed memory (multi-node) — an arbitrary number of computers connected by a network. Each node has its own memory; data must be explicitly passed between nodes (e.g. via MPI). Scales to thousands of nodes.
Hybrid — most modern HPC clusters combine both: multiple nodes (distributed), each with many cores (shared). Programs often use MPI across nodes and threading/multiprocessing within a node.
Accelerators (GPUs/FPGAs) — specialized hardware attached to a node that can execute thousands of simple operations simultaneously. Ideal for data-parallel tasks like matrix operations and deep learning.
Parallel computing: Hardware
When it comes to parallel computing, there are several ways (levels) in which we can speed up our analysis. From the bottom up:
- SIMD instructions: Most modern processors support vectorization — applying a single instruction to multiple data elements simultaneously, e.g. adding vectors
AandBelement-wise in one operation. - Hyper-Threading Technology (HTT): Intel’s Hyper-Threading exposes two logical cores per physical core by duplicating parts of the processor state. It does not double performance, but improves throughput when one logical core is stalled (e.g. waiting on memory).
- Multi-core processor: Most modern CPUs have multiple independent physical cores. A typical laptop in 2026 has 10–16 cores; server CPUs can have 64 or more.
Parallel computing: Hardware
- GPGPU (General-Purpose GPU computing): While modern CPUs have tens of cores, GPUs contain tens of thousands of smaller cores optimized for data-parallel work. Originally designed for graphics, GPUs are now central to scientific computing and machine learning (e.g. NVIDIA H100 has ~16,896 CUDA cores). The Digital Research Alliance (formerly Compute Canada) provides GPU access to researchers.
- HPC Cluster: A collection of computing nodes interconnected by a high-speed, low-latency network such as InfiniBand (not standard Ethernet). Nodes typically combine multi-core CPUs and GPUs.
- Grid Computing: A collection of loosely interconnected machines that may or may not be in the same physical location, for example HTCondor clusters. Lower bandwidth and higher latency than a dedicated HPC cluster.
Parallel computing: Terminology
CPU (Central Processing Unit): The main processor of a computer, consisting of one or more cores. A server may house multiple CPUs on separate sockets, each with its own local memory.
Socket: A physical slot on the motherboard that holds one CPU chip. Nodes with multiple sockets have NUMA (Non-Uniform Memory Access) architecture — memory attached to a different socket is slower to access.
Core: An independent processing unit within a CPU. Each core can execute its own thread or process simultaneously with other cores.
Node: A standalone computer — typically several CPUs, RAM, storage, and network interfaces. Nodes are networked together to form a cluster or supercomputer.
Cluster: A collection of nodes managed as a single system, sharing a job scheduler and file system.
Parallel computing: Terminology
Thread: The smallest unit of execution scheduled by the OS. Threads within the same process share memory, making communication fast but requiring synchronization to avoid race conditions.
Process: An independent program instance with its own memory space. Processes do not share memory by default — communication requires explicit mechanisms (pipes, sockets, shared memory).
Important
Python’s GIL: The standard Python interpreter — CPython (written in C, downloaded from python.org) — has a Global Interpreter Lock (GIL): a mutex that allows only one thread to execute Python bytecode at a time, even on a multi-core machine. This means Python threads cannot run truly in parallel. To achieve real parallelism in Python, use multiple processes (multiprocessing) so each process has its own interpreter and GIL.
Note: Python 3.13 introduced an experimental “free-threaded” (no-GIL) build, but it is not yet the default.
Parallel computing: CPU components
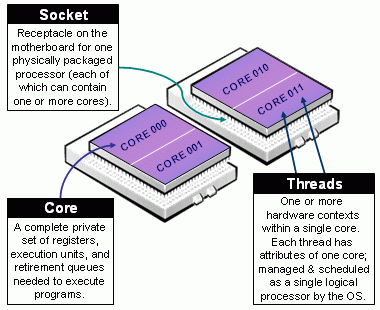
Taxonomy of CPUs (from https://slurm.schedmd.com/mc_support.html)
Parallel computing: Terminology
Job: A unit of work submitted to a cluster scheduler (e.g. SLURM). A job specifies the resources needed (cores, memory, time) and the commands to run. It may contain one or more tasks.
Task: A single executable unit within a job, typically mapped to one process running on one or more cores.
Worker: In Python’s multiprocessing and concurrent.futures, a worker is a spawned process that picks up and executes tasks from a shared queue. A Pool(4) creates 4 worker processes.
SLURM (Simple Linux Utility for Resource Management): The dominant open-source job scheduler on HPC clusters. Users submit jobs with sbatch; SLURM allocates nodes, queues work, and manages priorities.
Parallel computing: Components
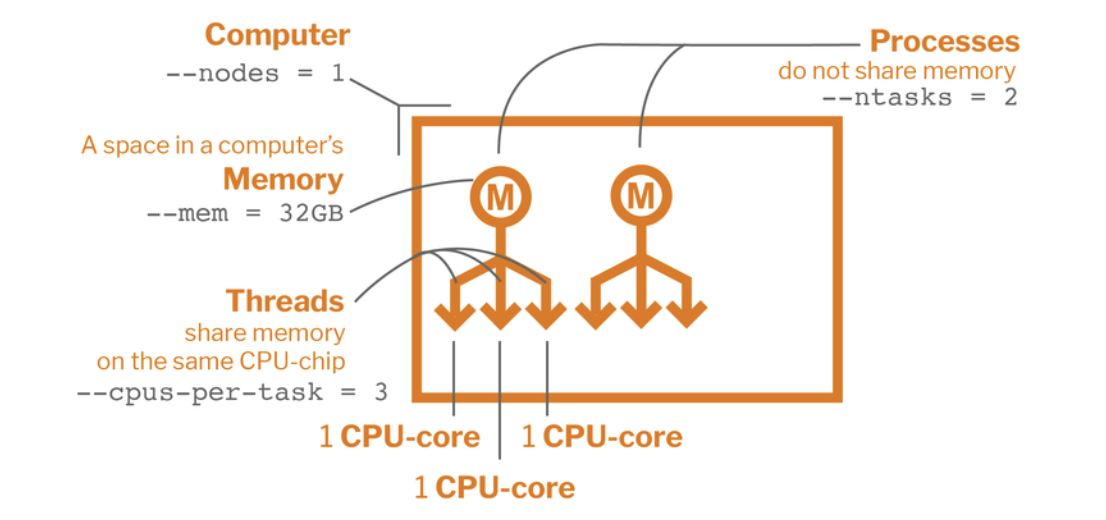
Parallel Computing Components with a SLURM script
Parallel Programming Models
There are several parallel programming models in common use:
- Shared Memory (without threads)
- Threads
- Distributed Memory / Message Passing (e.g. MPI)
- Data Parallel
- Hybrid
- Single Program Multiple Data (SPMD)
- Multiple Program Multiple Data (MPMD)
Do I need HPC?
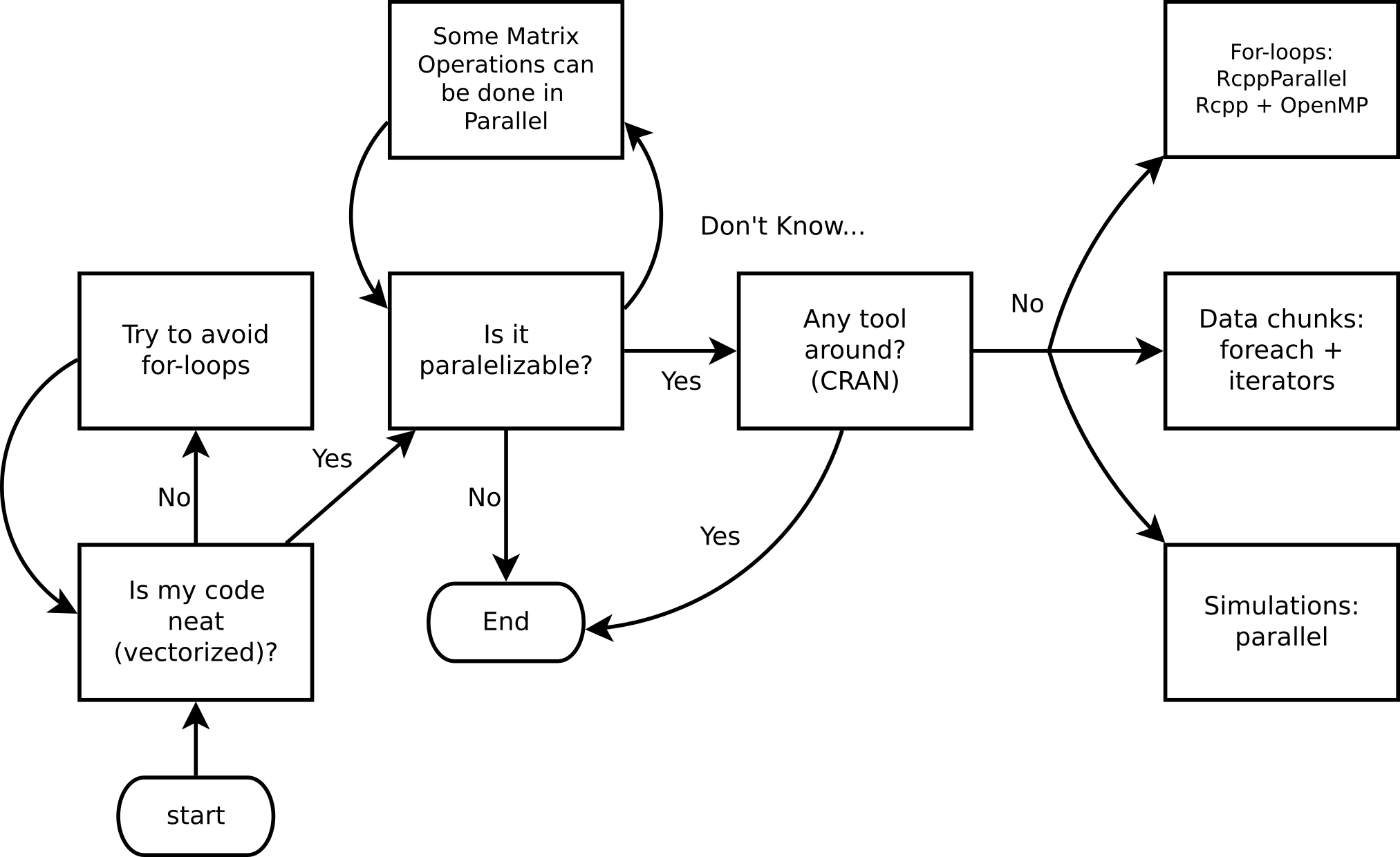
Ask yourself these questions before jumping into HPC!
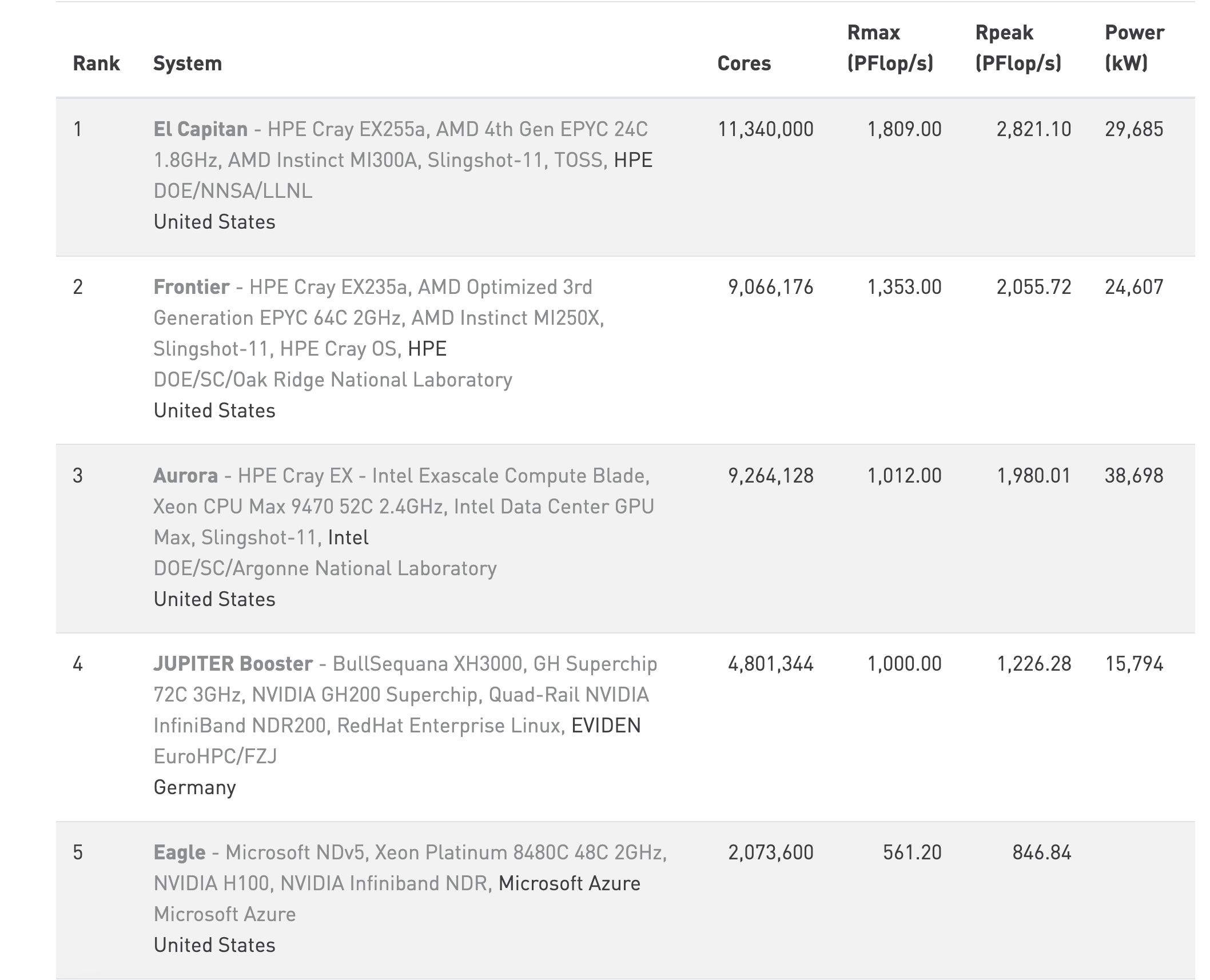
Top 10 HPC: www.top500.org
Parallel computing in Python
While there are several ways to do parallel computing in Python, we’ll focus on the following for explicit parallelism:
- multiprocessing: Python standard library module that supports spawning processes using an API similar to the threading module.
- concurrent.futures: A high-level interface for asynchronously executing callables using threads or processes.
Parallel computing in Python
- joblib: A set of tools to provide lightweight pipelining in Python, particularly useful for embarrassingly parallel for loops.
- multiprocess: A fork of
multiprocessingthat usesdillinstead ofpicklefor better serialization.
Implicit parallelism tools include numpy (BLAS-backed), numexpr, and tensorflow/pytorch for GPU acceleration.
Parallel computing in Python
More advanced options:
Embarrassingly Parallel
Many problems can be executed in an “embarrassingly parallel” way, whereby multiple independent pieces of a problem are executed simultaneously because the different pieces of the problem never really have to communicate with each other (except perhaps at the end when all the results are assembled).
Embarrassingly Parallel
The basic mode of an embarrassingly parallel operation can be seen with a Python for loop or list comprehension. Recall that we often want to apply the same function to each element of a list independently.
The map() function applies a function to each element of an iterable — this maps naturally onto parallel execution with Pool.map().
NOTE: NumPy operations are already vectorized (implicit parallelism via BLAS), but for arbitrary Python functions we need explicit parallelism.
Parallelization
Conceptually, the steps in the parallel procedure are:
- Split list
Xacross multiple cores - Copy the supplied function (and associated environment) to each of the cores
- Apply the supplied function to each subset of the list
Xon each of the cores in parallel - Assemble the results of all the function evaluations into a single list and return
The multiprocessing module
- Part of the Python standard library — no install required.
- Explicit parallelism via separate Python processes (avoids the GIL).
- Simple API:
Poolprovidesmap,starmap,apply_async, etc. - Clusters can use
Poollocally or tools likempi4pyremotely. - On Unix: supports forking (
fork/forkserver). On Windows: spawn only. - Let’s look at our session info
Example 1: Hello world!
This example demonstrates the basic structure of a parallel job in Python:
- Define a function (
hello_from_process) that each worker process will run — it reports its own process ID so we can confirm the work is spread across different processes. - Create a pool of 4 worker processes using
multiprocessing.get_context("fork").Pool. - Distribute the work with
pool.map(), which sends one copy ofxto each of the 4 workers and collects their return values. - Print the results — each line should show a different process ID, confirming parallel execution.
Hello from process #53316. I see x and it equals 20.
Hello from process #53317. I see x and it equals 20.
Hello from process #53318. I see x and it equals 20.
Hello from process #53319. I see x and it equals 20.Example 2: Parallel regressions
Problem: Run 999 independent univariate regressions on a wide dataset:
\[ y = X_i\beta_i + \varepsilon,\quad \varepsilon\sim N(0, \sigma^2_i), \quad i = 1,\ldots,999 \]
X shape: (500, 999)
y shape: (500,)Tip
Each regression is completely independent — a classic embarrassingly parallel problem.
Example 2: Parallel regressions (cont’d)
Key design rule: worker functions must be self-contained — pass all needed data as arguments, never rely on globals. We pack (col, y) into a tuple so pool.map can distribute it.
def fit_ols(args):
"""Fit OLS: y ~ x. Takes a (col, y) tuple; returns (intercept, slope)."""
col, y_vec = args
A = np.column_stack([np.ones(len(col)), col])
coeffs, _, _, _ = np.linalg.lstsq(A, y_vec, rcond=None)
return coeffs
# Build argument list: one (col, y) tuple per regression
job_args = [(X[:, j], y) for j in range(X.shape[1])]
# Serial baseline
ans_serial = [fit_ols(a) for a in job_args]
print("Serial coefficients (first 5 columns):")
print(np.array(ans_serial).T[:, :5])Serial coefficients (first 5 columns):
[[ 0.05840795 0.05881212 0.05851723 0.05793328 0.05841448]
[-0.01634667 -0.01148247 0.02937072 0.00873045 -0.00767652]]Example 2: Parallel regressions (cont’d 2)
import time
# Parallel — use fork context (required in Jupyter/Quarto on macOS)
ctx = multiprocessing.get_context("fork")
t0 = time.perf_counter()
ans_serial_timed = [fit_ols(a) for a in job_args]
t_serial = time.perf_counter() - t0
t0 = time.perf_counter()
with ctx.Pool(processes=4) as pool:
ans_parallel = pool.map(fit_ols, job_args)
t_parallel = time.perf_counter() - t0
print(f"Serial: {t_serial*1000:.1f} ms")
print(f"Parallel: {t_parallel*1000:.1f} ms")
print(f"Speedup: {t_serial/t_parallel:.2f}x")
# Verify results match
assert np.allclose(np.array(ans_serial_timed), np.array(ans_parallel))
print("Results match ✓")Serial: 17.3 ms
Parallel: 24.4 ms
Speedup: 0.71x
Results match ✓Example 2: Why is the parallel version slower?
Three reasons:
- Data overhead:
job_argscontains 999 copies ofy(each 500 × 8 bytes ≈ 4 KB), so ~4 MB is pickled and sent to workers — more work than the compute itself. - Tasks are too fast: each OLS fit takes ~0.04 ms. IPC and scheduling overhead per task easily exceeds that.
- BLAS is already parallel:
numpy.linalg.lstsqcalls multi-threaded BLAS internally — the “serial” loop is already exploiting multiple cores implicitly.
Important
Rule of thumb: Python multiprocessing pays off when tasks are slow pure-Python or I/O-bound work (≥ tens of ms each) and data transferred per task is small. For fast NumPy operations, vectorization or implicit BLAS parallelism is already better.
The influenza simulation next avoids all three pitfalls — tasks are slow Python loops with no BLAS shortcut, and each task only receives a small integer seed.
Extended Example: Influenza simulation
An altered version of Conway’s game of life
- People live on a torus grid, each individual having 8 neighbors.
- A susceptible individual interacting with an infected neighbor contracts influenza with probability depending on vaccination status:
- 60% if neither is vaccinated.
- 25% if only the susceptible individual is vaccinated.
- 40% if only the infected neighbor is vaccinated (reduces onward transmission).
- 8% if both are vaccinated.
Extended Example: Influenza simulation
- Infected individuals recover or die after one time step: 5% mortality, 95% recover.
We want to illustrate the importance of vaccination coverage. We simulate a grid of 900 (30 × 30) individuals 50 times to analyze: (a) the contagion curve, (b) the death toll under 0%, 50%, and 100% vaccination coverage.
More models like this: The SIRD model (Susceptible-Infected-Recovered-Deceased)
Conway’s Game of Flu: Python Setup
Conway’s Game of Flu: Simulation
def simulate_flu(pop_size=900, n_sick=10, n_vaccinated=0,
n_steps=15, seed=None):
rng = np.random.default_rng(seed)
n = int(np.sqrt(pop_size))
status = np.zeros((n, n), dtype=int) # all susceptible
# Infect initial individuals
sick_idx = rng.choice(pop_size, n_sick, replace=False)
status.flat[sick_idx] = INFECTED
# Assign vaccinated individuals
vaccinated = np.zeros(pop_size, dtype=bool)
if n_vaccinated > 0:
vacc_idx = rng.choice(pop_size, n_vaccinated, replace=False)
vaccinated[vacc_idx] = True
vaccinated = vaccinated.reshape(n, n)
deceased_counts = []
for _ in range(n_steps):
new_status = status.copy()
for i in range(n):
for j in range(n):
if status[i, j] == SUSCEPTIBLE:
# Check 8 neighbors (torus)
for di in [-1, 0, 1]:
for dj in [-1, 0, 1]:
if di == 0 and dj == 0:
continue
ni_, nj_ = (i + di) % n, (j + dj) % n
if status[ni_, nj_] == INFECTED:
both = vaccinated[i, j] and vaccinated[ni_, nj_]
only_self = vaccinated[i, j] and not vaccinated[ni_, nj_]
only_nb = not vaccinated[i, j] and vaccinated[ni_, nj_]
p = probs_transmit[3*both + 2*only_self + only_nb]
if rng.random() < p:
new_status[i, j] = INFECTED
break
else:
continue
break
elif status[i, j] == INFECTED:
if rng.random() < prob_death:
new_status[i, j] = DECEASED
else:
new_status[i, j] = RECOVERED
status = new_status
deceased_counts.append((status == DECEASED).sum())
return np.array(deceased_counts)How does the simulation look?
Deceased by time step:
Step 1: 11
Step 2: 31
Step 3: 66
Step 4: 82
Step 5: 86
...
Step 16: 88
Step 17: 88
Step 18: 88
Step 19: 88
Step 20: 88Results: Effect of Vaccination Coverage
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(8, 5))
steps = np.arange(1, 16)
ax.boxplot(stats_nobody, positions=steps - 0.25, widths=0.2,
patch_artist=True, boxprops=dict(facecolor="tomato"),
medianprops=dict(color="black"), showfliers=False)
ax.boxplot(stats_half, positions=steps, widths=0.2,
patch_artist=True, boxprops=dict(facecolor="gray"),
medianprops=dict(color="black"), showfliers=False)
ax.boxplot(stats_all, positions=steps + 0.25, widths=0.2,
patch_artist=True, boxprops=dict(facecolor="steelblue"),
medianprops=dict(color="black"), showfliers=False)
ax.set_xlabel("Time step")
ax.set_ylabel("Cumulative deceased")
ax.set_title("Influenza deaths: 0% (red) vs 50% (gray) vs 100% (blue) vaccination coverage")
ax.set_xticks(steps)
plt.tight_layout()
plt.show()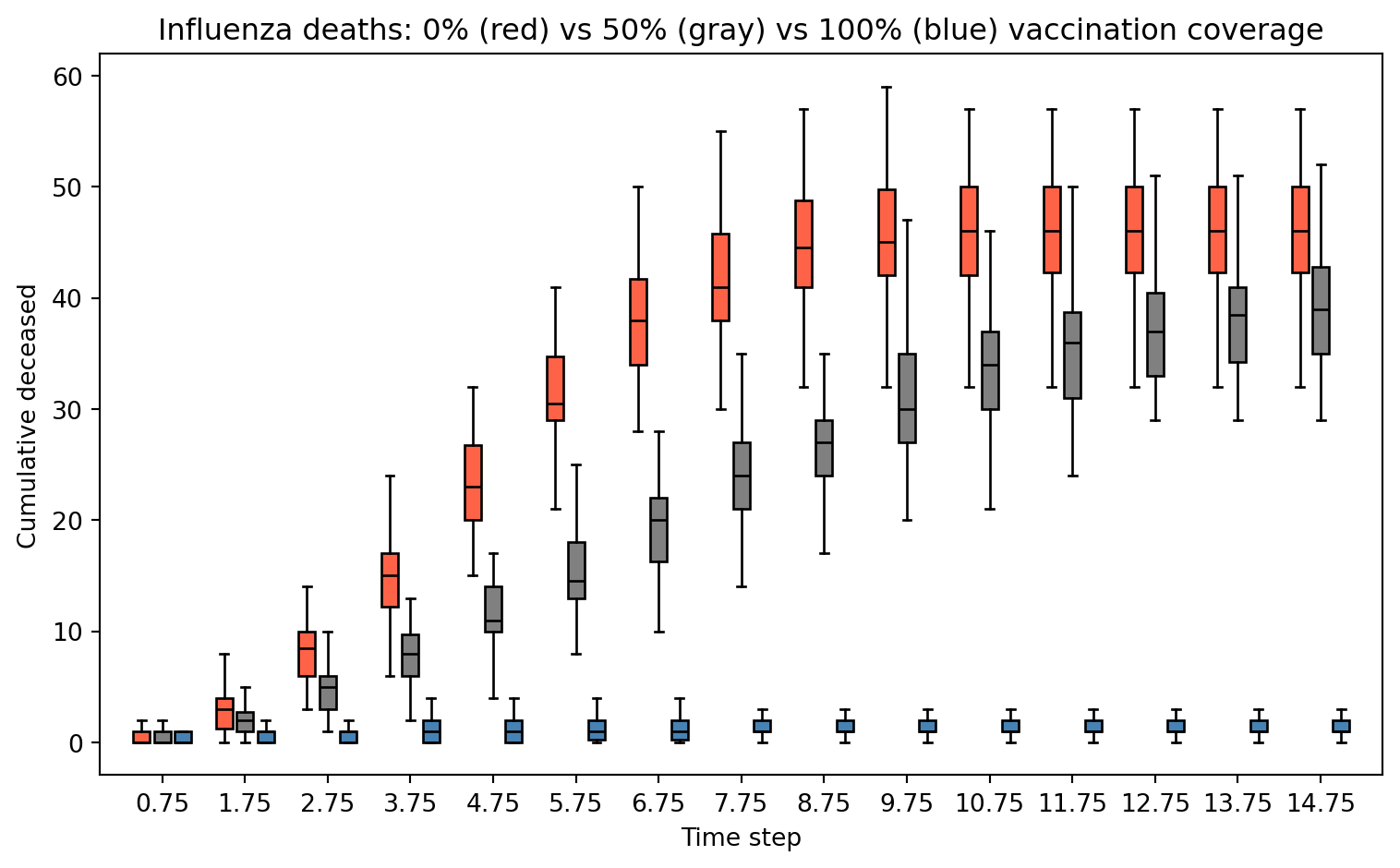
Speed things up: Timing under serial implementation
We will use time.time() to measure how much time it takes to complete 50 simulations serially versus in parallel using 4 cores.
Speed things up: Parallel with Pool.map
Python’s multiprocessing.Pool.map is the primary tool for embarrassingly parallel workloads:
def run_one(seed):
return simulate_flu(pop_size=900, n_sick=10,
n_vaccinated=900, n_steps=20, seed=seed)
ctx = multiprocessing.get_context("fork")
start = time.time()
with ctx.Pool(processes=4) as pool:
ans_parallel = pool.map(run_one, range(50))
time_parallel = time.time() - start
print(f"Parallel time (4 cores): {time_parallel:.2f}s")
print(f"Speedup: {time_serial/time_parallel:.2f}x")Parallel time (4 cores): 0.35s
Speedup: 2.97xSpeed things up: Parallel with concurrent.futures
concurrent.futures.ProcessPoolExecutor is a higher-level alternative with a cleaner API. Pass mp_context to use fork (required in Jupyter/Quarto on macOS — same reason as Pool):
ctx = multiprocessing.get_context("fork")
start = time.time()
with concurrent.futures.ProcessPoolExecutor(max_workers=4, mp_context=ctx) as executor:
ans_futures = list(executor.map(run_one, range(50)))
time_futures = time.time() - start
print(f"ProcessPoolExecutor time (4 cores): {time_futures:.2f}s")
print(f"Speedup vs serial: {time_serial/time_futures:.2f}x")ProcessPoolExecutor time (4 cores): 0.39s
Speedup vs serial: 2.63xParallel Workflow in Python
(Usually) We do the following:
- Define a top-level function (must be picklable — no lambdas!)
- Create a
Pool(orProcessPoolExecutor) - Submit work:
pool.map(),pool.starmap(),pool.apply_async() - Collect results and close/join the pool (use
withstatement)
Serial vs Parallel Time
Serial time: 1.027s
Pool.map time: 0.346s
ProcessPoolExecutor: 0.390s
Speedup (Pool.map): 2.97xWe care about the elapsed (wall clock) time.
Note: For short tasks, process-creation overhead can outweigh the benefit — parallelism pays off for computationally expensive work.
Cloud Computing (a.k.a. on-demand computing)
HPC clusters, super-computers, etc. need not to be bought… you can rent:
These services provide more than just computing (storage, data analysis, etc.). But for computing and storage, there are other free resources, e.g.:
There are many ways to run Python in the cloud
Running Python in:
- Google Cloud: https://cloud.google.com/python
- Amazon Web Services: https://aws.amazon.com/developer/language/python/
- Microsoft Azure: https://azure.microsoft.com/en-us/develop/python/
Submitting jobs
- A key feature of cloud services and remote servers → interact via command line.
- You will need to familiarize with running Python scripts from the terminal.
- Use
python script.pyor make the script executable.
Submitting jobs
Imagine we have the following Python script (group_stats.py):
Running in background (bash)
This will run a non-interactive Python session and put all output to group_stats.out:
Submitting jobs
The & at the end makes sure the job is submitted and does not wait for it to end.
Alternatively, capture stdout and stderr separately:
Try it yourself (5 mins)!
Python as a script
Python scripts can be executed as programs directly if you specify the interpreter path in a shebang line. This is a script named since_born.py:
This Python script can be executed in various ways…
Python as a program
For this we would need to change it to an executable. In Unix you can use the chmod command: chmod +x since_born.py. This allows:
Python in a bash script
In the case of running jobs in a cluster or something similar, we usually need to have a bash script. Here we have a file named since_born_bash.sh that calls python:
Which we would execute like this:
SLURM Job Script Example
A typical SLURM submission script for a Python parallel job:
Submit with: sbatch submit.sh
Summary
- Parallel computing can speed up things.
- Not always needed… need to make sure that you are taking advantage of vectorization.
Summary
- Most of the time we look at “Embarrassingly parallel computing.”
- In Python, explicit parallelism can be achieved using the multiprocessing module:
- Define a top-level picklable function
- Create a pool:
multiprocessing.Pool(n_cores)orconcurrent.futures.ProcessPoolExecutor(n_cores) - Make the call:
pool.map(),pool.starmap(),executor.map() - Stop the pool (use
withstatement for automatic cleanup)
- Regardless of the Cloud computing service, we will use
python script.pyor bash scripts with SLURM to submit jobs.
Resources
- multiprocessing — Process-based parallelism
- concurrent.futures — High-level async execution
- joblib documentation
- Dask documentation
- mpi4py documentation
- Ray documentation
- Digital Research Alliance (Compute Canada)
For more, checkout the Python parallel computing overview
Practical Example: XGBoost on Bike Share Data
We revisit the Toronto Bike Share 2023 dataset from the previous lecture to predict trip duration (minutes) using XGBRegressor.
Two levels of parallelism in XGBoost:
- Within one model: tree construction is parallelized across cores via
nthread - Across models (hyperparameter search): use
GridSearchCV(n_jobs=4)to train multiple configs simultaneously — setnthread=1per model so cores are not doubled up
Note
Install with: pip install xgboost scikit-learn requests
XGBoost: Load & Prepare Bike Share Data
Let’s use the same data as last week
import requests, zipfile, io
import numpy as np
import pandas as pd
import xgboost as xgb
import time
from sklearn.model_selection import train_test_split, GridSearchCV
# Load May 2023 from Toronto Open Data (same source as Lecture 9)
base_url = "https://ckan0.cf.opendata.inter.prod-toronto.ca"
pkg = requests.get(base_url + "/api/3/action/package_show",
params={"id": "bike-share-toronto-ridership-data"}).json()
for r in pkg["result"]["resources"]:
if "2023" in r["name"]:
url_2023 = r["url"]; break
z = zipfile.ZipFile(io.BytesIO(requests.get(url_2023).content))
csv_file = [f for f in z.namelist() if f.endswith('.csv')][4] # May 2023
bike = pd.read_csv(z.open(csv_file), encoding='latin-1')
print(f"Loaded {bike.shape[0]:,} trips from {csv_file}")Loaded 589,217 trips from bikeshare-ridership-2023/Bike share ridership 2023-05.csvXGBoost: Feature Engineering
bike.columns = (bike.columns.str.strip()
.str.replace(r'\s+', '_', regex=True)
.str.lower())
bike['start_time'] = pd.to_datetime(bike['start_time'])
bike['trip_duration_min'] = bike['trip_duration'] / 60
bike['hour'] = bike['start_time'].dt.hour
bike['day_of_week'] = bike['start_time'].dt.dayofweek
bike['month'] = bike['start_time'].dt.month
bike['is_weekend'] = (bike['day_of_week'] >= 5).astype(int)
bike['is_member'] = (bike['user_type'] == 'Annual Member').astype(int)
bike = bike[(bike['trip_duration_min'] >= 1) & (bike['trip_duration_min'] <= 120)]
def build_features(df):
out = pd.DataFrame({'is_weekend': df['is_weekend'], 'is_member': df['is_member']},
index=df.index)
for col, period, K in [('hour', 24, 3), ('day_of_week', 7, 2), ('month', 12, 2)]:
for k in range(1, K + 1):
out[f'{col}_sin_k{k}'] = np.sin(2 * np.pi * k * df[col] / period)
out[f'{col}_cos_k{k}'] = np.cos(2 * np.pi * k * df[col] / period)
return out
X = build_features(bike)
y = bike['trip_duration_min']
X_tr, X_te, y_tr, y_te = train_test_split(X, y, test_size=0.2, random_state=65)
print(f"Features: {X.shape[1]} | Train: {X_tr.shape[0]:,} Test: {X_te.shape[0]:,}")Features: 16 | Train: 467,048 Test: 116,762XGBoost: Comparing 1, 4, and All Cores
results = {}
for nthread in [1, 4, multiprocessing.cpu_count()]:
model = xgb.XGBRegressor(
n_estimators=100, max_depth=5, nthread=nthread,
random_state=65, verbosity=0
)
t0 = time.perf_counter()
model.fit(X_tr, y_tr)
elapsed = time.perf_counter() - t0
rmse = np.sqrt(((model.predict(X_te) - y_te) ** 2).mean())
results[nthread] = elapsed
print(f"nthread={nthread:2d}: {elapsed:.2f}s RMSE={rmse:.2f} min")
print(f"\nSpeedup (1 → 4 cores): {results[1]/results[4]:.2f}x")
print(f"Speedup (1 → all cores): {results[1]/results[multiprocessing.cpu_count()]:.2f}x")nthread= 1: 1.39s RMSE=14.71 min
nthread= 4: 0.61s RMSE=14.71 min
nthread= 8: 0.77s RMSE=14.71 min
Speedup (1 → 4 cores): 2.27x
Speedup (1 → all cores): 1.81xXGBoost: Parallel Hyperparameter Search
The standard way to parallelize hyperparameter search is GridSearchCV(n_jobs=...) from scikit-learn, which uses joblib internally and avoids all notebook multiprocessing pitfalls.
param_grid = {
"max_depth": [3, 5, 7],
"learning_rate": [0.05, 0.1, 0.2],
"subsample": [0.7, 1.0],
"min_child_weight": [1, 10],
}
n_configs = (len(param_grid["max_depth"]) * len(param_grid["learning_rate"])
* len(param_grid["subsample"]) * len(param_grid["min_child_weight"]))
print(f"Grid: {n_configs} configs × 3 CV folds = {n_configs * 3} fits")
base_model = xgb.XGBRegressor(
n_estimators=100,
nthread=1, # 1 thread per model; parallelism is across CV fits
random_state=65, verbosity=0
)Grid: 36 configs × 3 CV folds = 108 fitsXGBoost: Parallel Hyperparameter Search (cont’d)
t0 = time.perf_counter()
gs_serial = GridSearchCV(base_model, param_grid, cv=3, n_jobs=1,
scoring="neg_root_mean_squared_error")
gs_serial.fit(X_tr, y_tr)
t_serial = time.perf_counter() - t0
t0 = time.perf_counter()
gs_parallel = GridSearchCV(base_model, param_grid, cv=3, n_jobs=4,
scoring="neg_root_mean_squared_error")
gs_parallel.fit(X_tr, y_tr)
t_parallel = time.perf_counter() - t0
print(f"Serial (n_jobs=1): {t_serial:.2f}s")
print(f"Parallel (n_jobs=4): {t_parallel:.2f}s (speedup: {t_serial/t_parallel:.2f}x)")
print(f"\nBest params: {gs_parallel.best_params_}")
print(f"Best CV RMSE: {-gs_parallel.best_score_:.2f} min")Serial (n_jobs=1): 132.81s
Parallel (n_jobs=4): 55.54s (speedup: 2.39x)
Best params: {'learning_rate': 0.05, 'max_depth': 5, 'min_child_weight': 10, 'subsample': 0.7}
Best CV RMSE: 14.53 minXGBoost: Does Tuning Help?
Retrain the best configuration with more estimators and compare to the default on the held-out test set:
# Default model
default_model = xgb.XGBRegressor(
n_estimators=100, max_depth=5, learning_rate=0.1,
nthread=multiprocessing.cpu_count(), random_state=65, verbosity=0
)
default_model.fit(X_tr, y_tr)
rmse_default = np.sqrt(((default_model.predict(X_te) - y_te) ** 2).mean())
# Best config from grid search, retrained with more estimators
best_params = gs_parallel.best_params_
tuned_model = xgb.XGBRegressor(
n_estimators=200, **best_params,
nthread=multiprocessing.cpu_count(), random_state=65, verbosity=0
)
tuned_model.fit(X_tr, y_tr)
rmse_tuned = np.sqrt(((tuned_model.predict(X_te) - y_te) ** 2).mean())
print(f"Default (depth=5, lr=0.1, n=100): RMSE = {rmse_default:.2f} min")
print(f"Tuned {best_params}, n=200: RMSE = {rmse_tuned:.2f} min")
print(f"Improvement: {rmse_default - rmse_tuned:.2f} min ({(rmse_default - rmse_tuned)/rmse_default*100:.1f}%)")Default (depth=5, lr=0.1, n=100): RMSE = 14.70 min
Tuned {'learning_rate': 0.05, 'max_depth': 5, 'min_child_weight': 10, 'subsample': 0.7}, n=200: RMSE = 14.70 min
Improvement: -0.00 min (-0.0%)Tip
Hyperparameter tuning has limits. The biggest gains usually come from better features, not better hyperparameters. Here we only use temporal features — adding trip distance or station capacity (as in Lecture 9) would reduce RMSE far more than any grid search.
Submitting XGBoost to a SLURM Cluster
Save your training script as train_xgboost.py:
import requests, zipfile, io, sys
import numpy as np, pandas as pd, xgboost as xgb
from sklearn.model_selection import train_test_split
nthread = int(sys.argv[1]) if len(sys.argv) > 1 else 4
# Load full 2023 bike share data (all months)
base_url = "https://ckan0.cf.opendata.inter.prod-toronto.ca"
pkg = requests.get(base_url + "/api/3/action/package_show",
params={"id": "bike-share-toronto-ridership-data"}).json()
for r in pkg["result"]["resources"]:
if "2023" in r["name"]:
url_2023 = r["url"]; break
z = zipfile.ZipFile(io.BytesIO(requests.get(url_2023).content))
csvs = [f for f in z.namelist() if f.endswith('.csv')]
bike = pd.concat([pd.read_csv(z.open(f), encoding='latin-1') for f in csvs],
ignore_index=True)
bike.columns = bike.columns.str.strip().str.replace(r'\s+','_',regex=True).str.lower()
bike['start_time'] = pd.to_datetime(bike['start_time'])
bike['trip_duration_min'] = bike['trip_duration'] / 60
bike['hour'] = bike['start_time'].dt.hour
bike['day_of_week'] = bike['start_time'].dt.dayofweek
bike['month'] = bike['start_time'].dt.month
bike['is_weekend'] = (bike['day_of_week'] >= 5).astype(int)
bike['is_member'] = (bike['user_type'] == 'Annual Member').astype(int)
bike = bike[(bike['trip_duration_min'] >= 1) & (bike['trip_duration_min'] <= 120)]
def build_features(df):
out = pd.DataFrame({'is_weekend': df['is_weekend'], 'is_member': df['is_member']},
index=df.index)
for col, period, K in [('hour', 24, 3), ('day_of_week', 7, 2), ('month', 12, 2)]:
for k in range(1, K + 1):
out[f'{col}_sin_k{k}'] = np.sin(2 * np.pi * k * df[col] / period)
out[f'{col}_cos_k{k}'] = np.cos(2 * np.pi * k * df[col] / period)
return out
X = build_features(bike)
y = bike['trip_duration_min']
X_tr, X_te, y_tr, y_te = train_test_split(X, y, test_size=0.2, random_state=65)
model = xgb.XGBRegressor(n_estimators=500, max_depth=6,
nthread=nthread, verbosity=0, random_state=65)
model.fit(X_tr, y_tr)
rmse = np.sqrt(((model.predict(X_te) - y_te) ** 2).mean())
print(f"RMSE: {rmse:.2f} min | n_train={X_tr.shape[0]:,} nthread={nthread}")Submitting XGBoost to a SLURM Cluster (cont’d)
SLURM script submit_xgb.sh — request cores and pass $SLURM_CPUS_PER_TASK directly to nthread:
Submit with:
Overview of HPC
Using Flynn’s classical taxonomy, we can classify parallel computing according to the following two dimensions:
- Type of instruction: Single vs Multiple
- Data stream: Single vs Multiple




Parallel computing: Software
Implicit parallelization:
- tensorflow: Machine learning framework with automatic GPU support
- pytorch: Deep learning framework with GPU/multi-node support
- numpy: Vectorized operations via BLAS/LAPACK (multi-threaded)
- numexpr: Multi-threaded evaluation of array expressions
- dask: Parallel collections with lazy evaluation
Explicit parallelization (DIY):
- CUDA + numba: GPU programming for Python
- mpi4py: Python bindings for MPI (multi-node)
- multiprocessing: Process-based parallelism (built-in)
- concurrent.futures: High-level thread/process pools (built-in)
- joblib: Easy parallelism for loops, with caching
- Ray: Distributed computing framework for ML and data processing
- Dask: Scales from single machine to cluster with familiar APIs