This lecture presents a deeper introduction to plotnine, a Python package that implements the grammar of graphics (similar to R’s ggplot2), providing better graphics options than matplotlib’s default plots.
This week
We will also dig into non-parametric regression with splines and generalized additive models (GAMs).
A generalized additive model (GAM) predicts \(y\) by adding up learned smooth functions of the predictors:
Nonlinear: each \(s_j(\cdot)\) is a flexible curve (often a spline)
Regularized: we control “wiggliness” with a penalty (bias–variance tradeoff)
Fits the ML pattern: choose flexibility by minimizing training loss + complexity penalty
Interpretable: you can plot each learned effect \(s_j(x_j)\) (partial effect curves)
Generalized: works for continuous, binary, counts via a link \(g(\cdot)\)
Mental model: like linear regression, but each coefficient is replaced by a smooth curve.
Background
plotnine is based on the grammar of graphics, the same underlying philosophy as R’s ggplot2. In the Python ecosystem, we use pandas for data manipulation (similar to R’s dplyr), and plotnine for visualization.
The tidyverse philosophy of readable, chainable operations translates well to Python with method chaining in pandas.
Layers, pandas and method chaining
We should take a step back and discuss Python’s data manipulation ecosystem.
plotnine behaves very similarly to pandas. They share a philosophy of readable, chainable operations.
In pandas, operations are typically chained using method calls on DataFrames.
Each method takes a DataFrame and returns a new DataFrame.
Method chaining in Python uses the . operator (similar to R’s pipe).
You can also use parentheses to break long chains across multiple lines.
Flights data
To illustrate many of today’s visualization examples we will look at the flights data from the nycflights13 package. They are all flights that departed from NYC airports (JFK, LGA, EWR) in 2013.
from nycflights13 import flightsprint("Columns:", flights.columns.tolist())print("Shape:", flights.shape)
An example using method chaining: subset the flights data to LAX, and take the mean arrival delay times by year, month, day.
We need to start with the data, query or boolean indexing to filter to the desired destination (LAX), groupby to prepare the groups that we want to aggregate over, then agg to take the mean.
Variable names should use only lowercase letters, numbers, and _
Use _ to separate words within a name (snake_case)
Method chains should have each method on its own line, indented
Wrap long chains in parentheses for cleaner formatting
Each chained method should be indented for readability
Example:
short_flights = (flights .query('air_time < 60'))
Flights data in more detail
The nycflights13 package also provides hourly airport weather data for the three NYC airports (the origin). Let’s join the flights data with the weather data so we can look at more interesting relationships in our visualizations.
Looks like we can join these datasets on year, month, day, hour and origin (which is the origin airport). We can examine the relationship between flight delays and weather at the origin airports (JFK, LGA, EWR).
A merge with how='left' will keep all of the observations in the left DataFrame (flights) and merge with the observations in the right DataFrame (weather at origin).
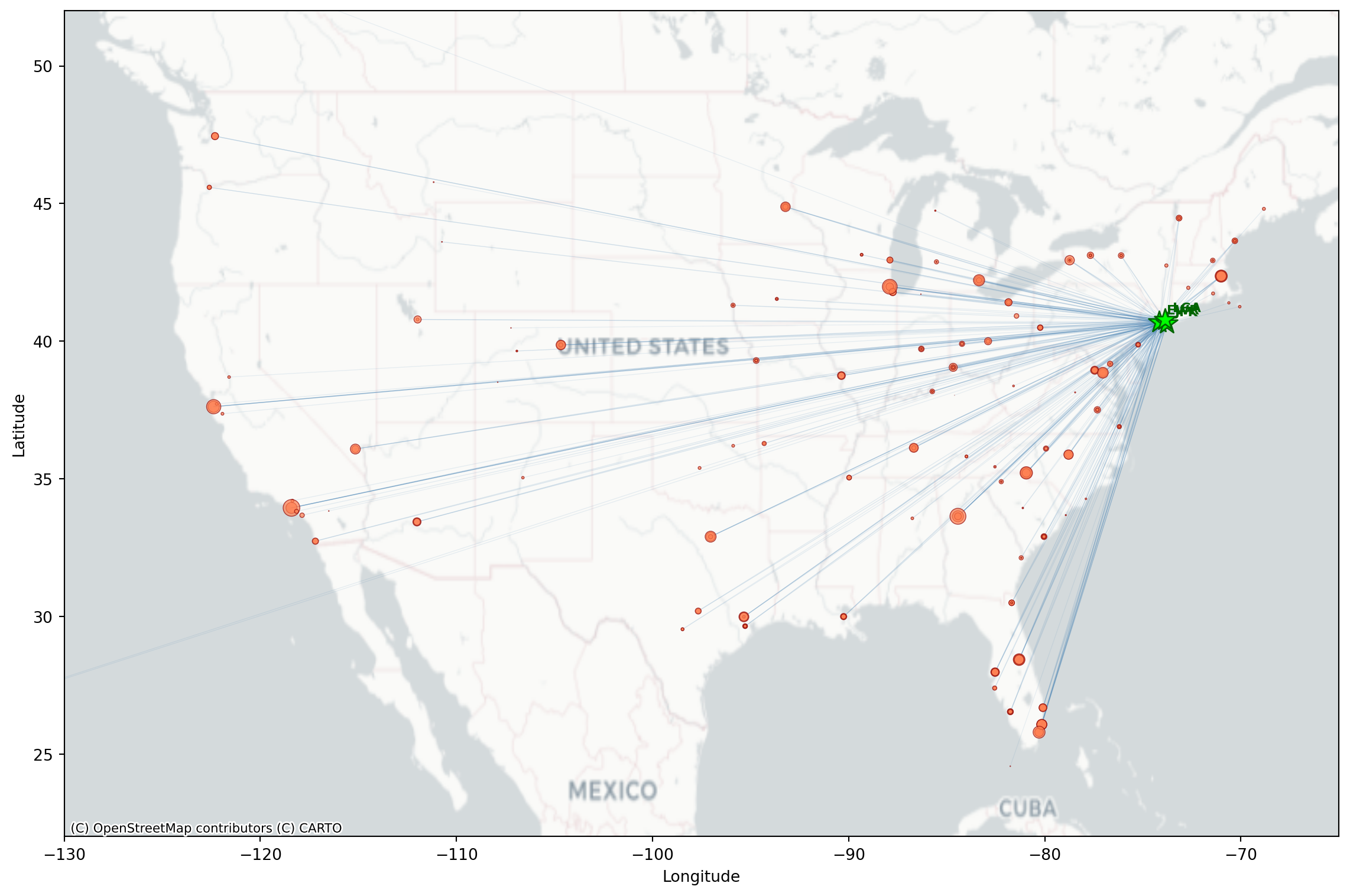
The nycflights13 package also includes airport coordinates. We can merge these in with flights to map where are the popular NYC destinations.
from nycflights13 import airports# get routes by origin (EWR, JFK, LGA) and destination, count the number of flights perflight_routes = (flights .groupby(['origin', 'dest']) .size() .reset_index(name='n_flights'))# extract geospatial and merging info about the airportsairports[['faa', 'name', 'lat', 'lon']].head()
faa
name
lat
lon
0
04G
Lansdowne Airport
41.130472
-80.619583
1
06A
Moton Field Municipal Airport
32.460572
-85.680028
2
06C
Schaumburg Regional
41.989341
-88.101243
3
06N
Randall Airport
41.431912
-74.391561
4
09J
Jekyll Island Airport
31.074472
-81.427778
Flight Routes Data
Merge flight routes with geospatial information (latitude and longitude) by origin (it is the faa column in airports) and rename to have dest_lat, dest_lon along with origin_lat and origin_lon
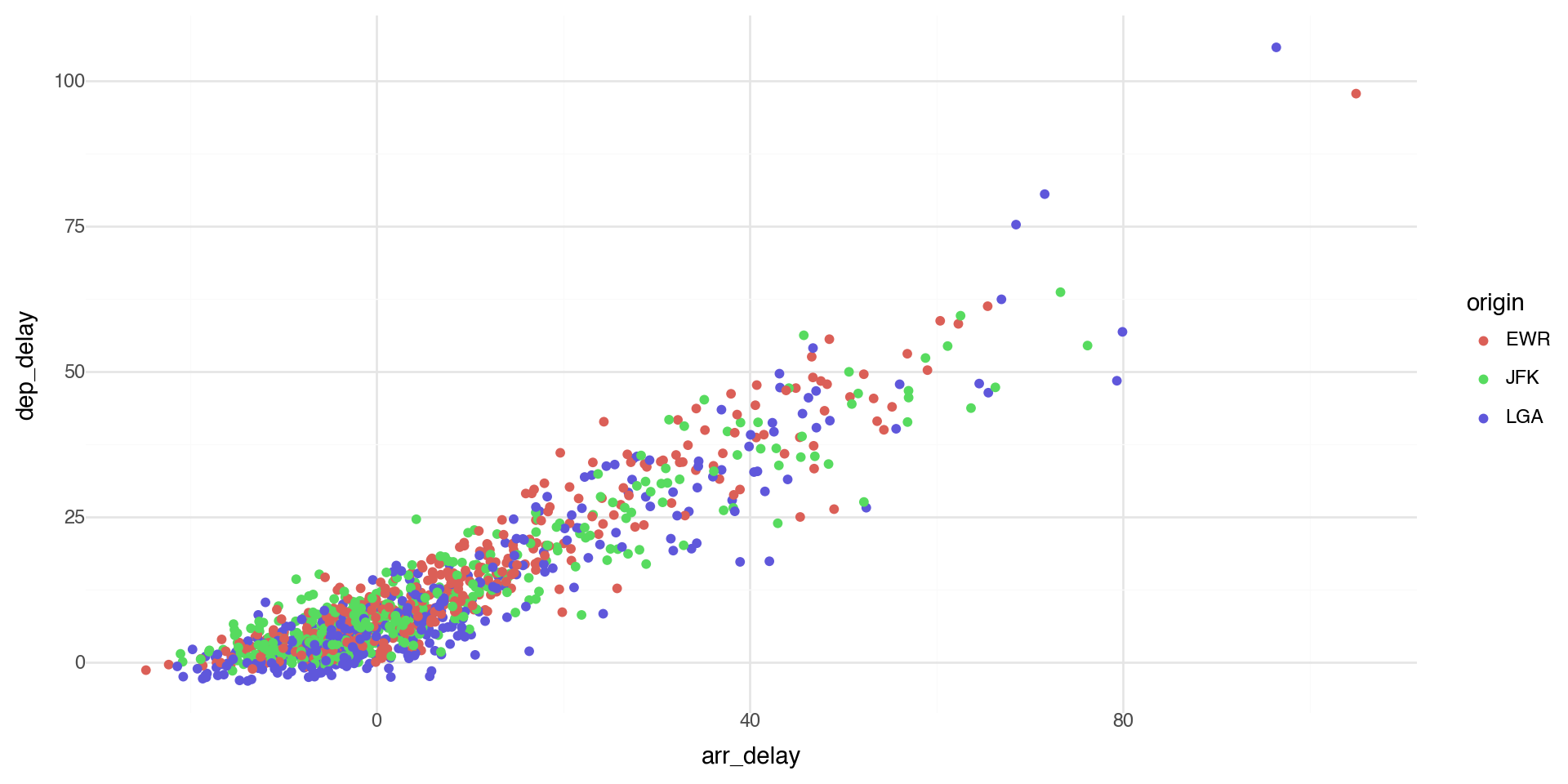
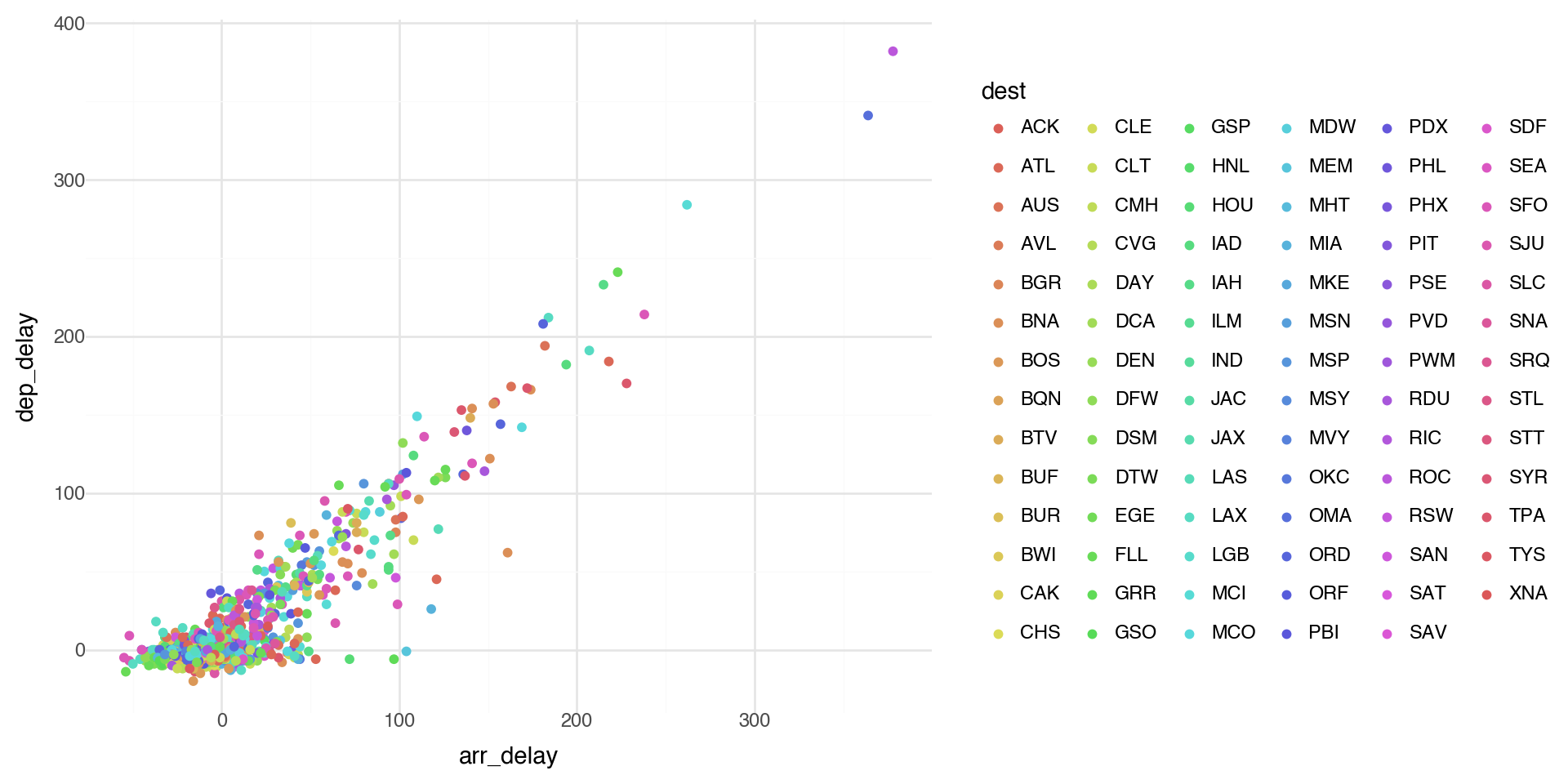
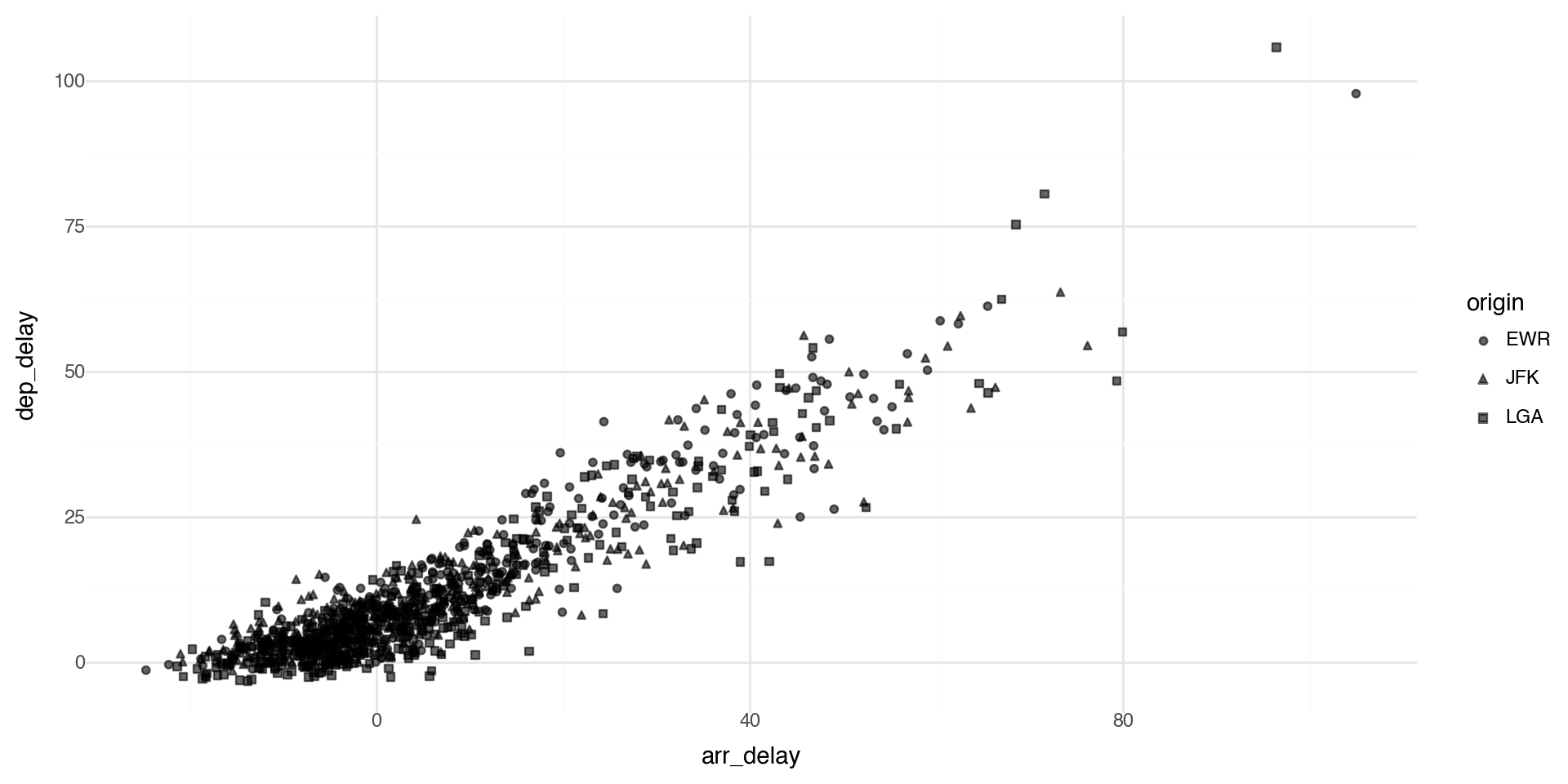
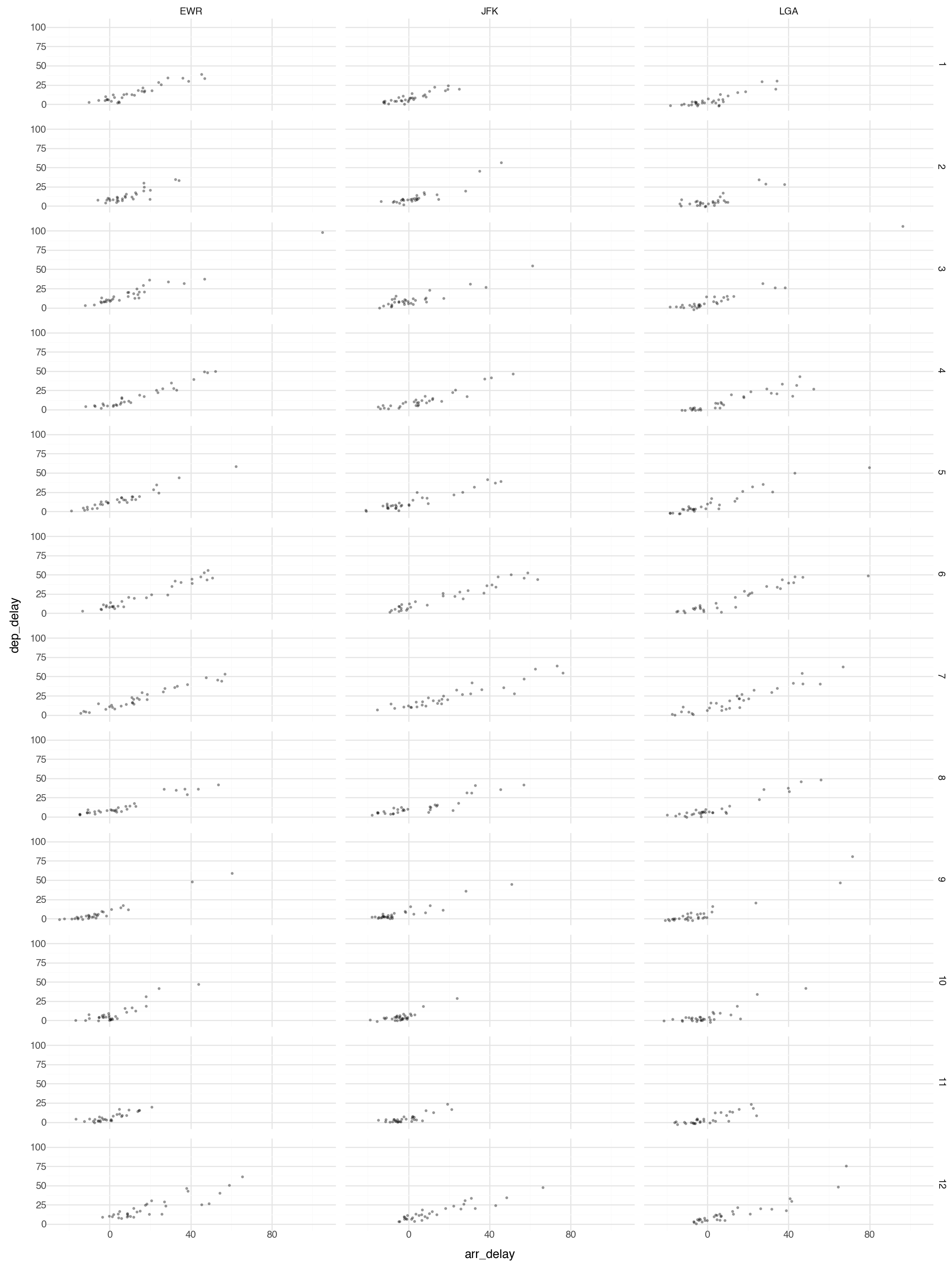
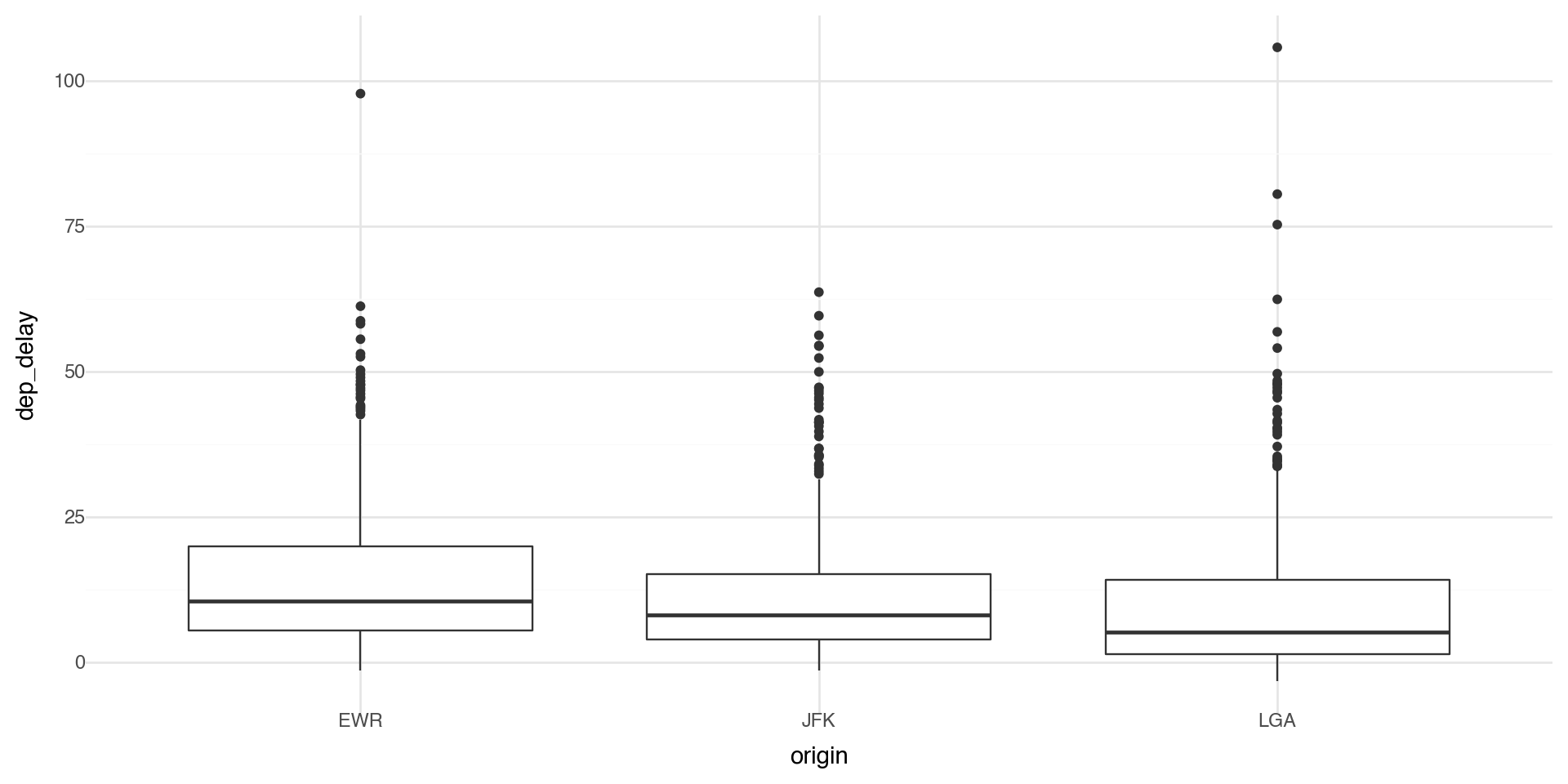
As expected, we see that if a flight has a late departure, it has a late arrival.
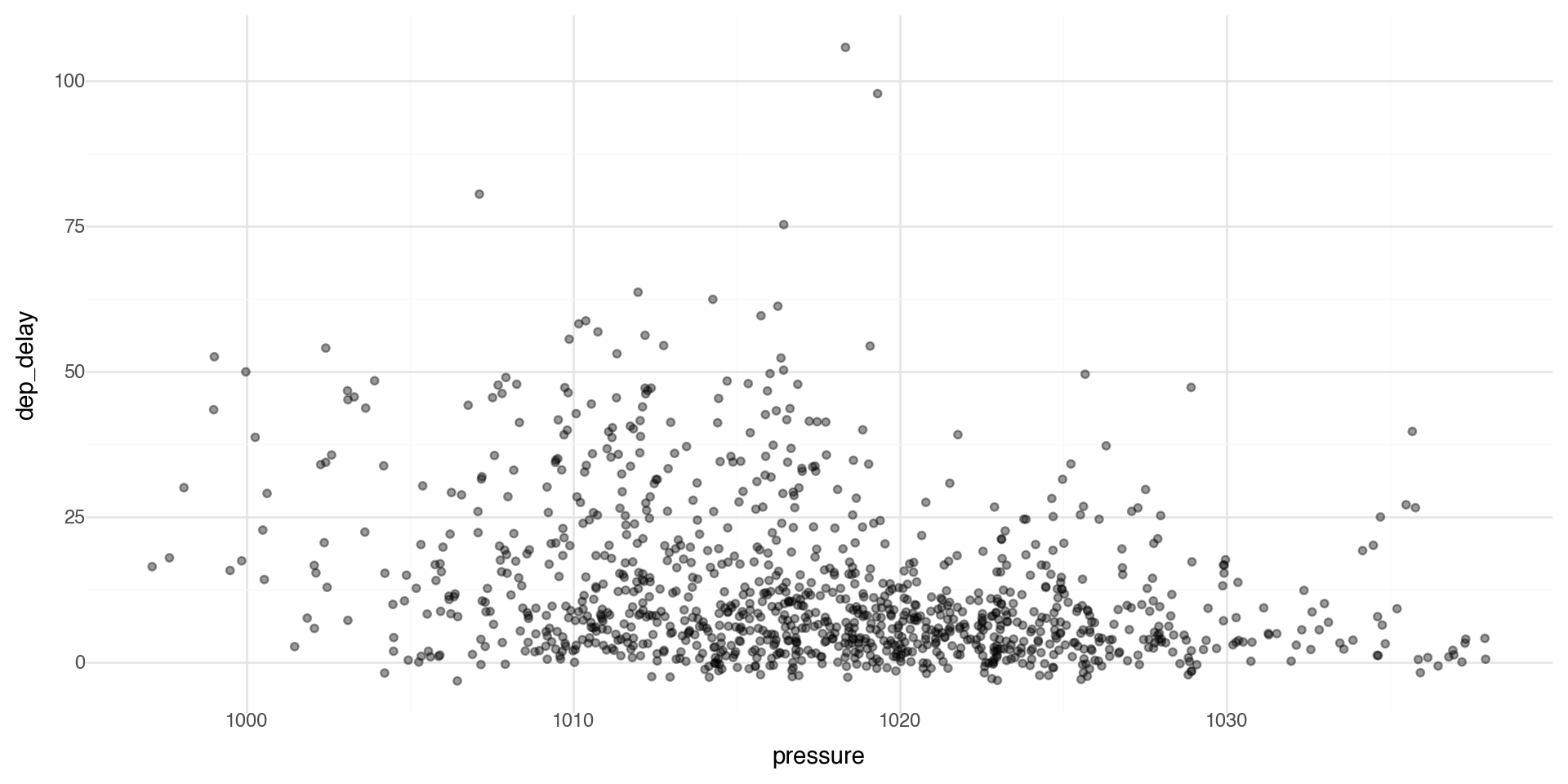
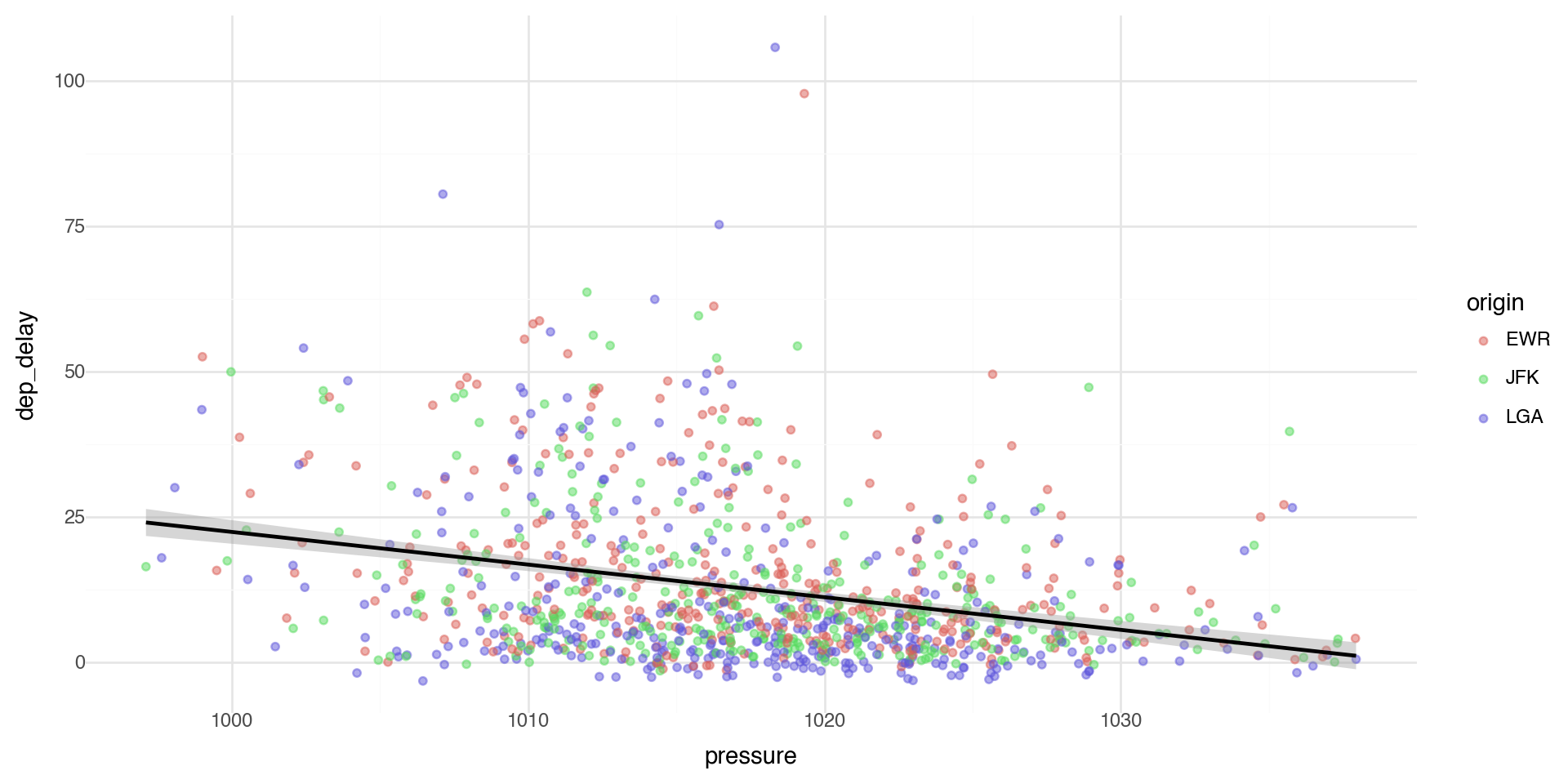
Another basic scatterplot
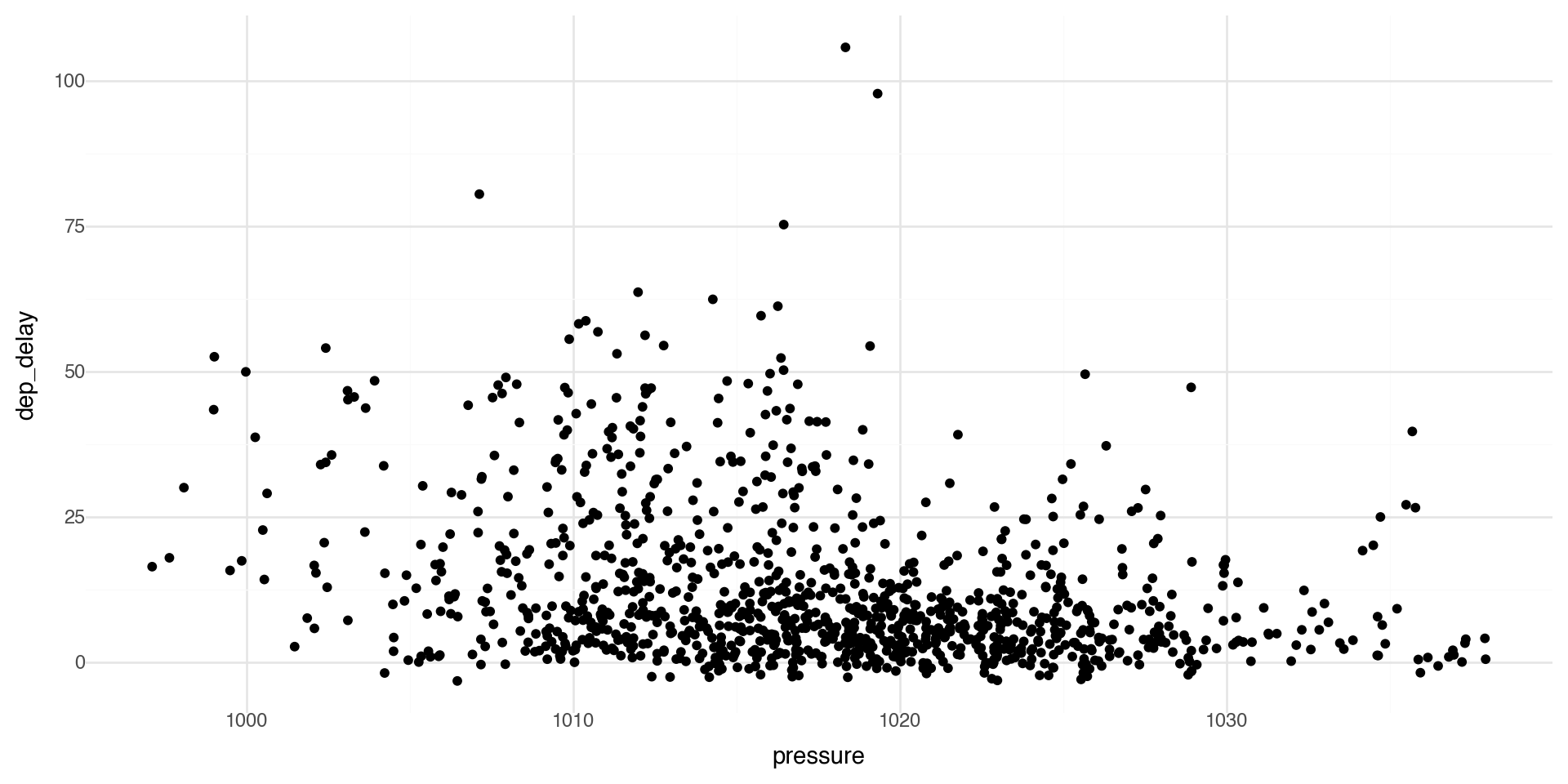
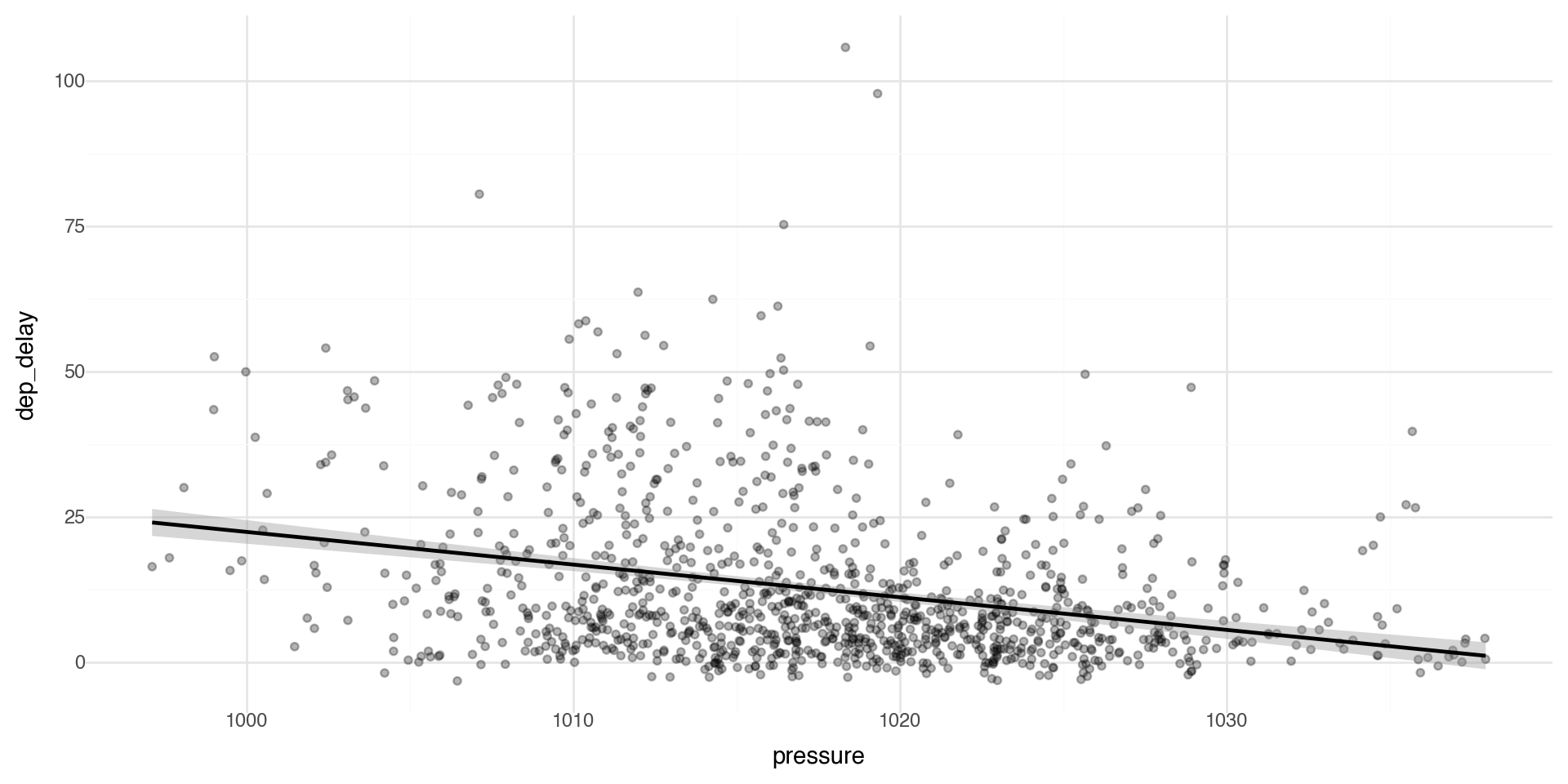
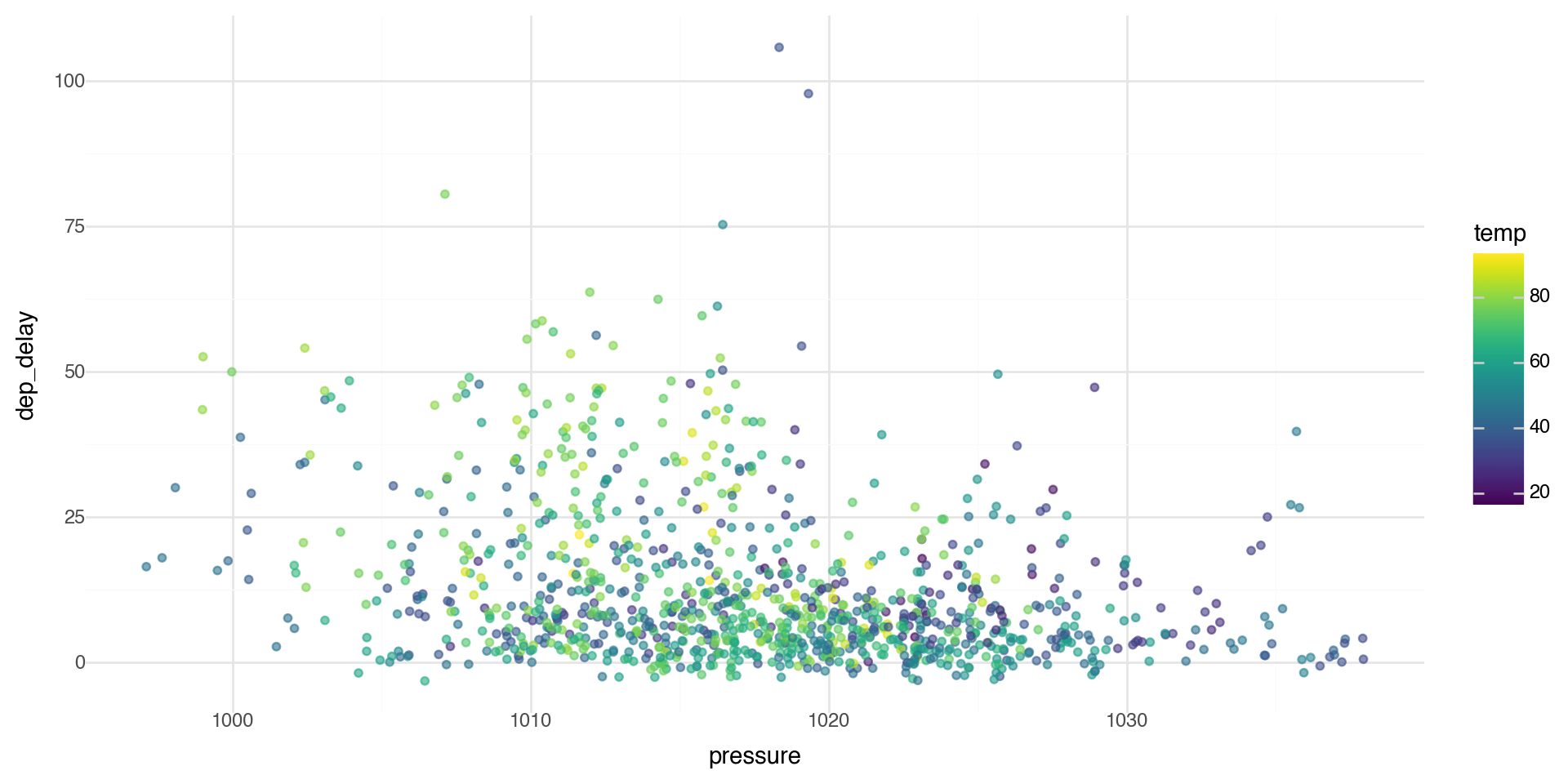
We can see if there is a relationship between departure delays and pressure (low pressure means clouds and precipitation, high pressure means better weather).
The alpha control can go in the layer that you are plotting, for example in the geom_point(alpha = ) layer we can directly control the transparency of the points (0 is fully transparent, 1 is fully opaque).
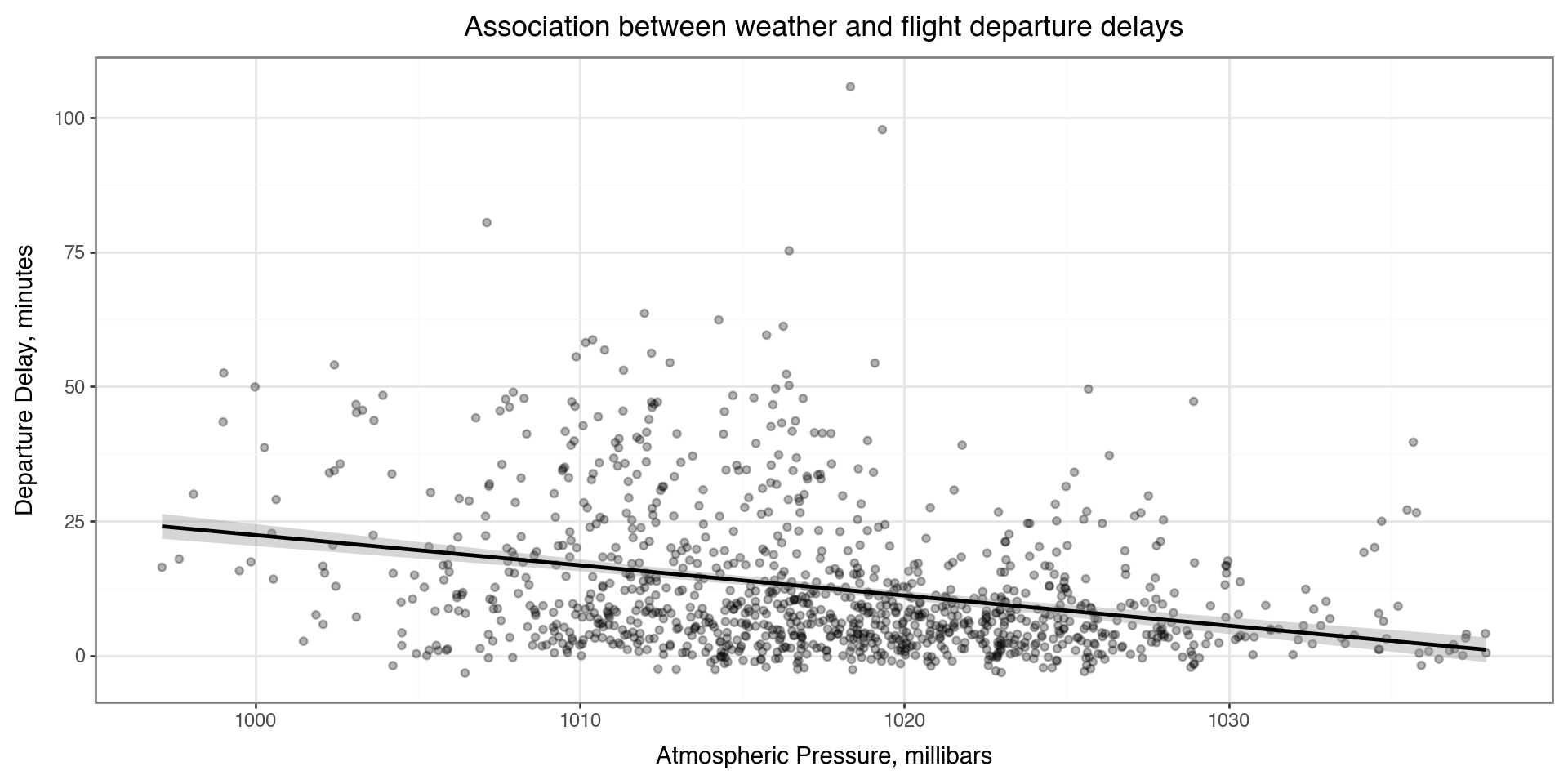
You can make nicer axes and add titles with the labs layer
Also showing a minimal theme that removes the background grey theme_bw() (has a plot border) or theme_minimal() (no plot border, lighter and sparser grid lines)
You can convey information about your data by mapping the aesthetics in your plot to the variables in your dataset. For example, you can map the colors of your points to the origin variable to reveal groupings.
plotnine chooses colors, and adds a legend, automatically.
By default plotnine uses up to 6 shapes with shape= in the aes() aesthetics. If there are more, some of your data is not plotted!! (At least it warns you.)
If we control aesthetics manually in the layer such as geom_point() (i.e. outside aes()), they become fixed constants for that geom, not variables mapped from the data.
One more important detail in plotnine: if you write aes(color='blue'), that’s a mapping (to the literal string “blue”), not a fixed aesthetic, so you’ll often get an odd legend. Fixed values should be outside aes(), but coloring by a variable (such as a group) should be inside aes().
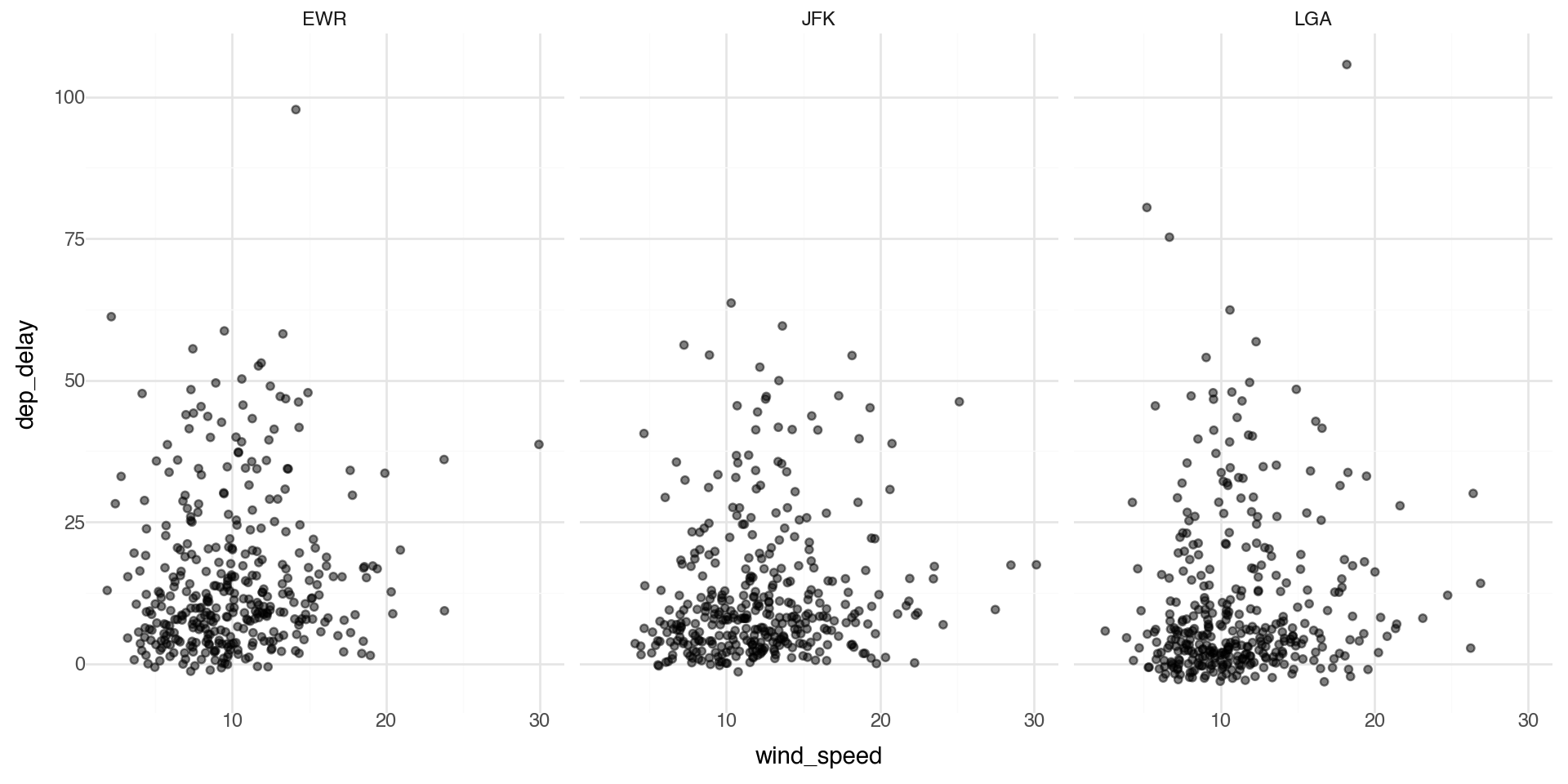
Note this plot is probably too large and busy for practical use, but it gives you the idea what is possible with faceting.
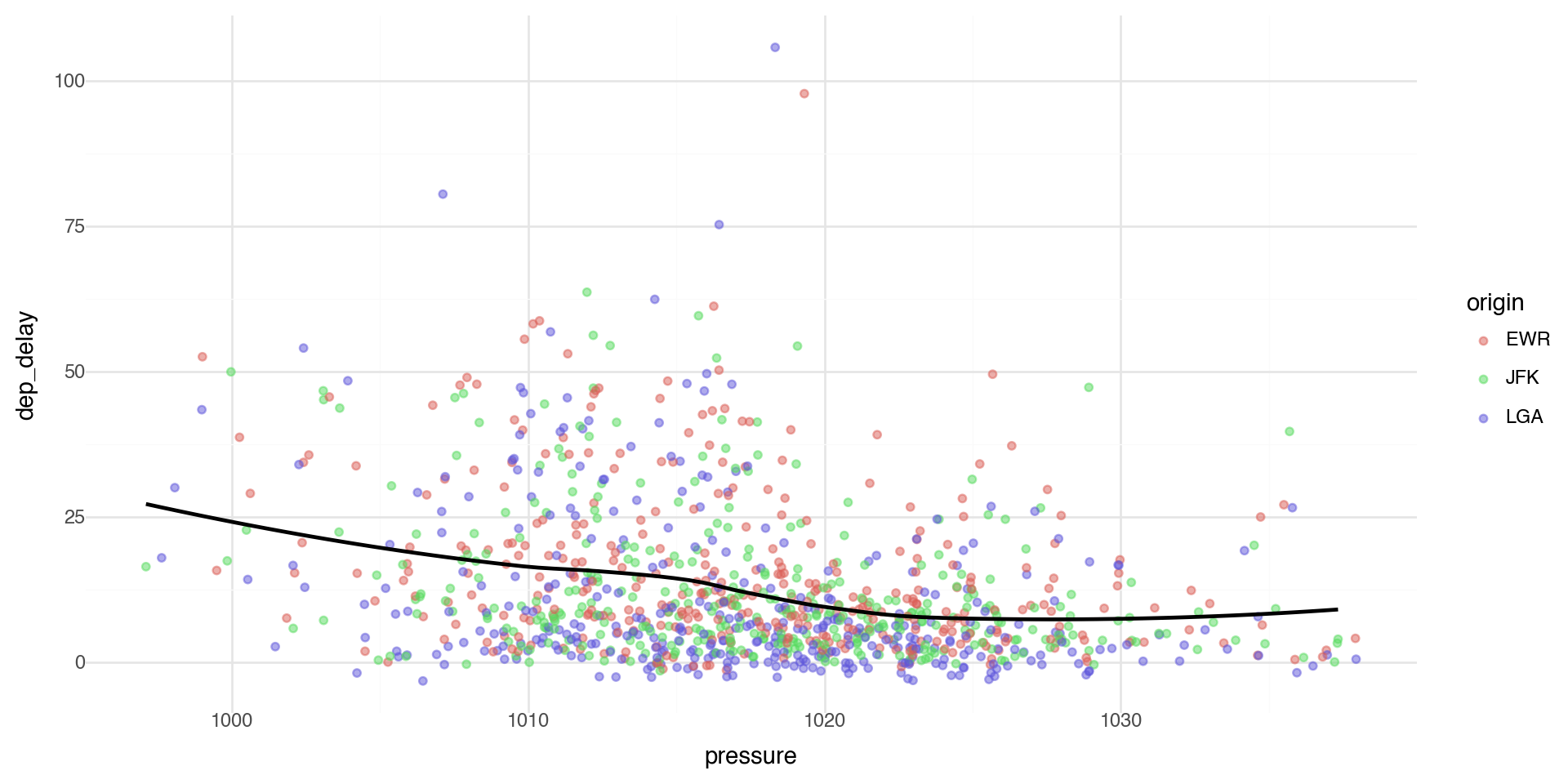
Geometric Objects 1
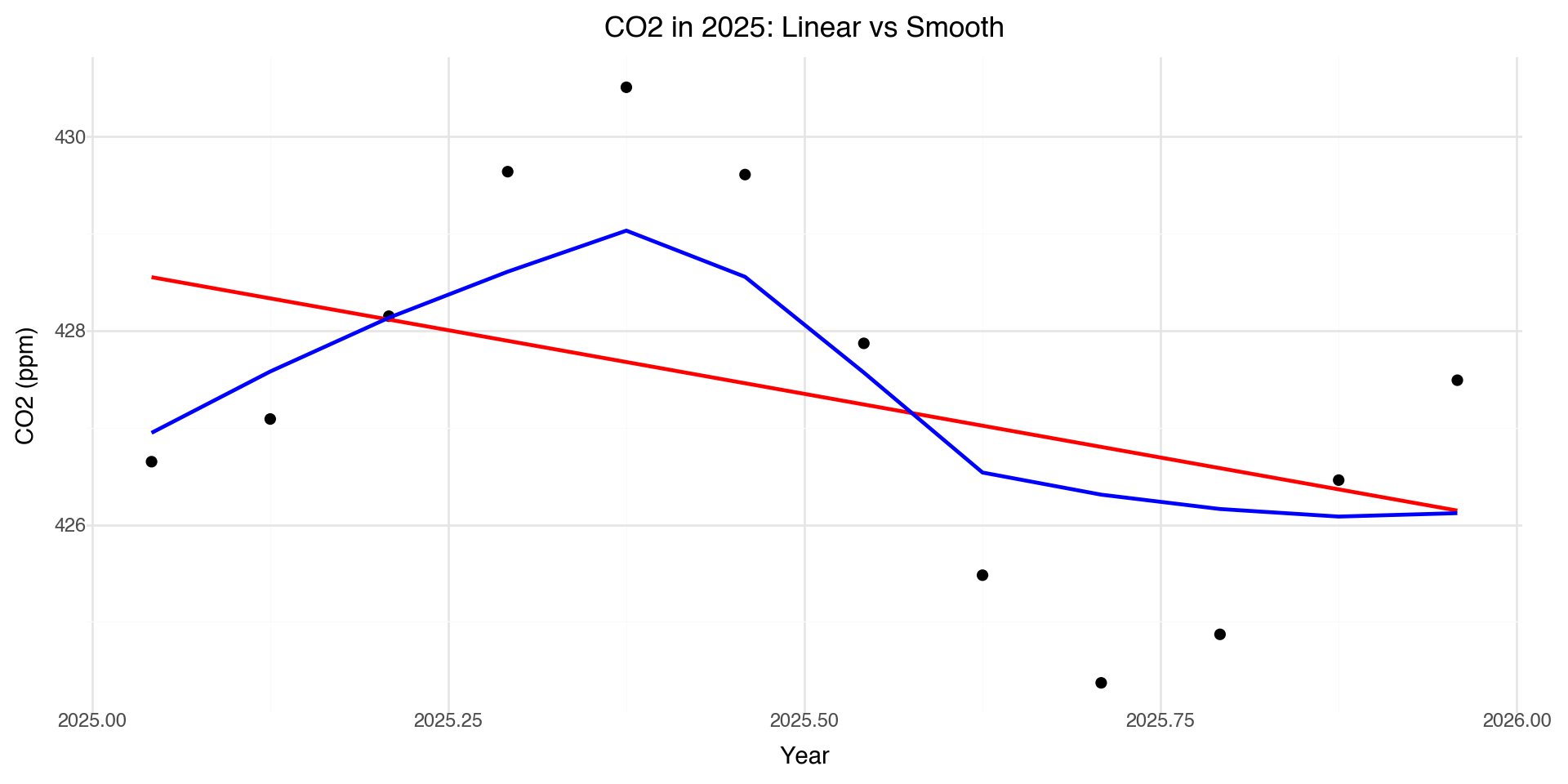
Geometric objects are used to control the type of plot you draw. Let’s plot a smoothed line fitted to the scatterplot data between pressure and departure delay.
To display multiple geoms in the same plot, add multiple geom functions to ggplot(), for example geom_point and geom_smooth
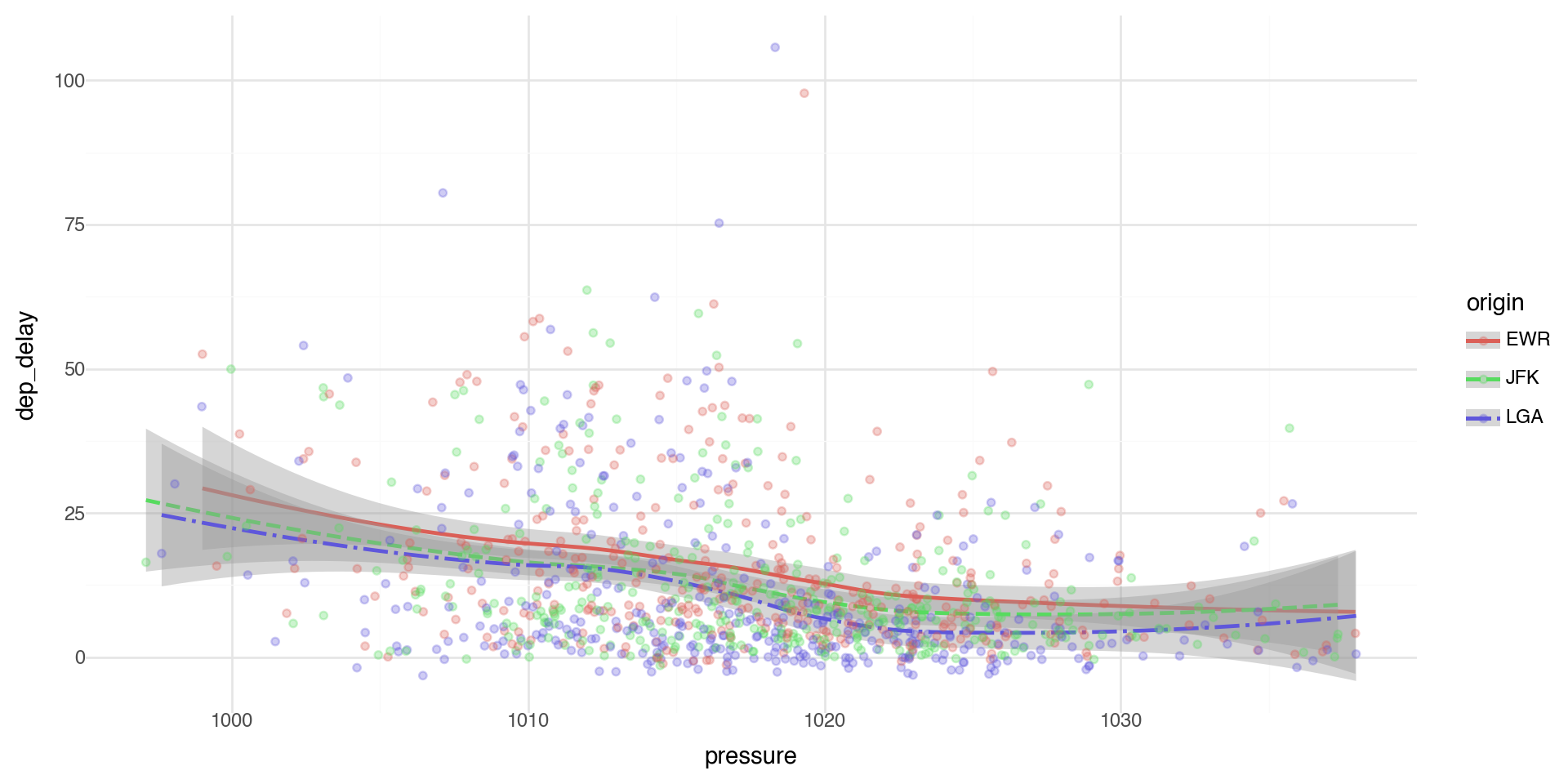
Multiple Geoms 2
If you place mappings in a geom function, plotnine will use these mappings to extend or overwrite the global mappings for that layer only. This makes it possible to display different aesthetics in different layers.
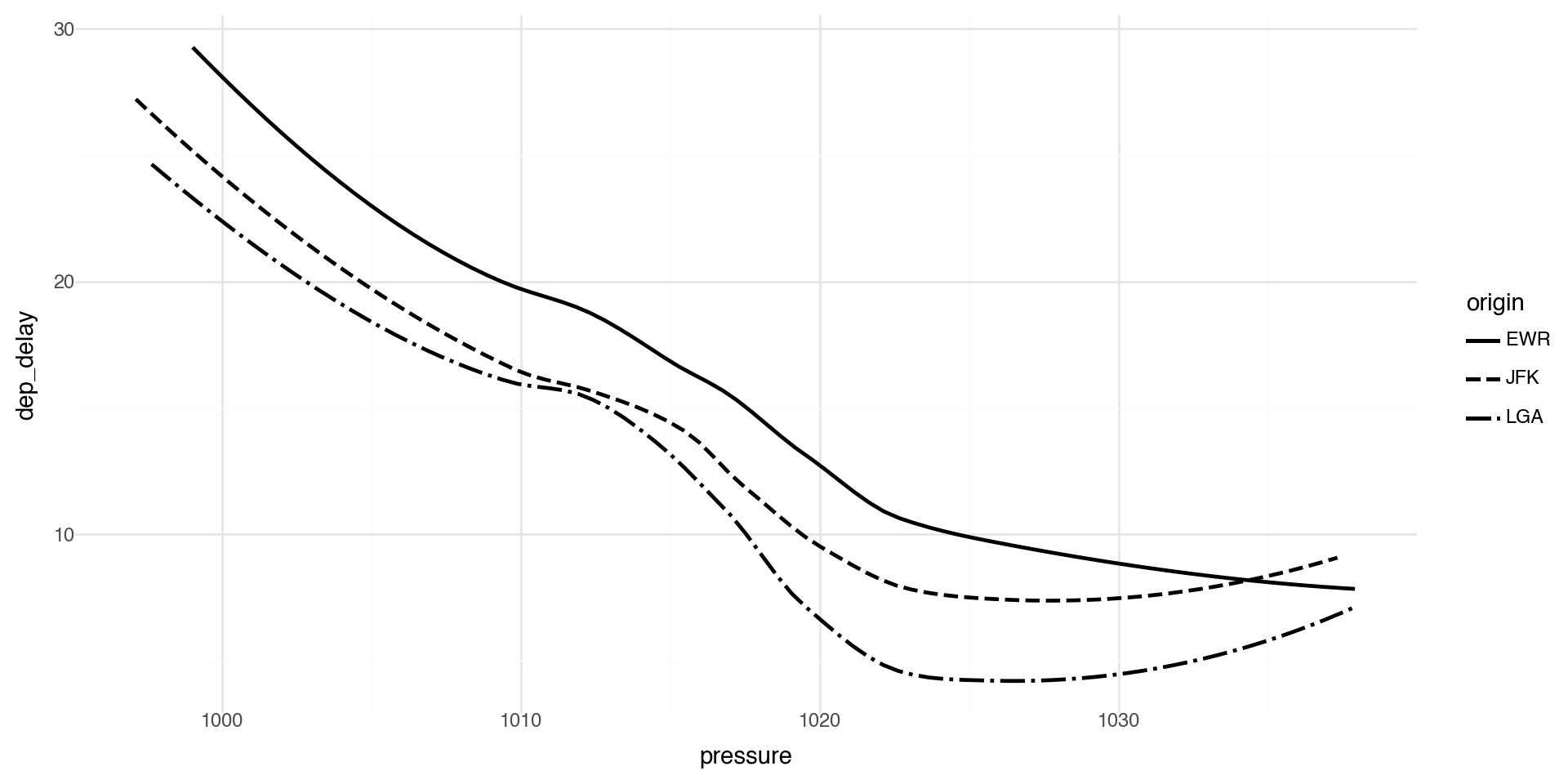
You can use the same idea to specify different data for each layer. Here, our smooth line displays just a subset of the dataset, the flights departing from JFK. The local data argument in geom_smooth() overrides the global data argument in ggplot() for that layer only.
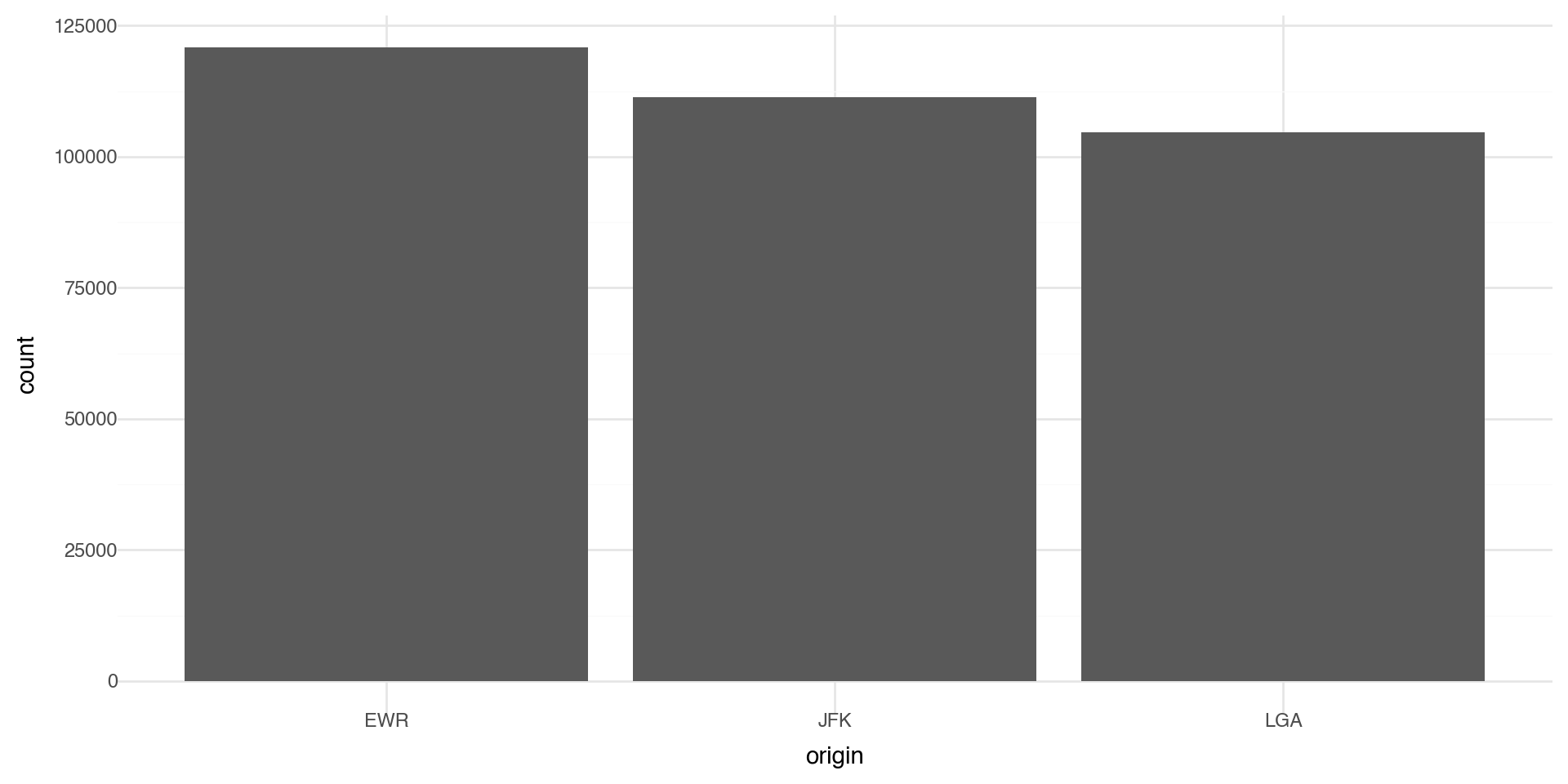
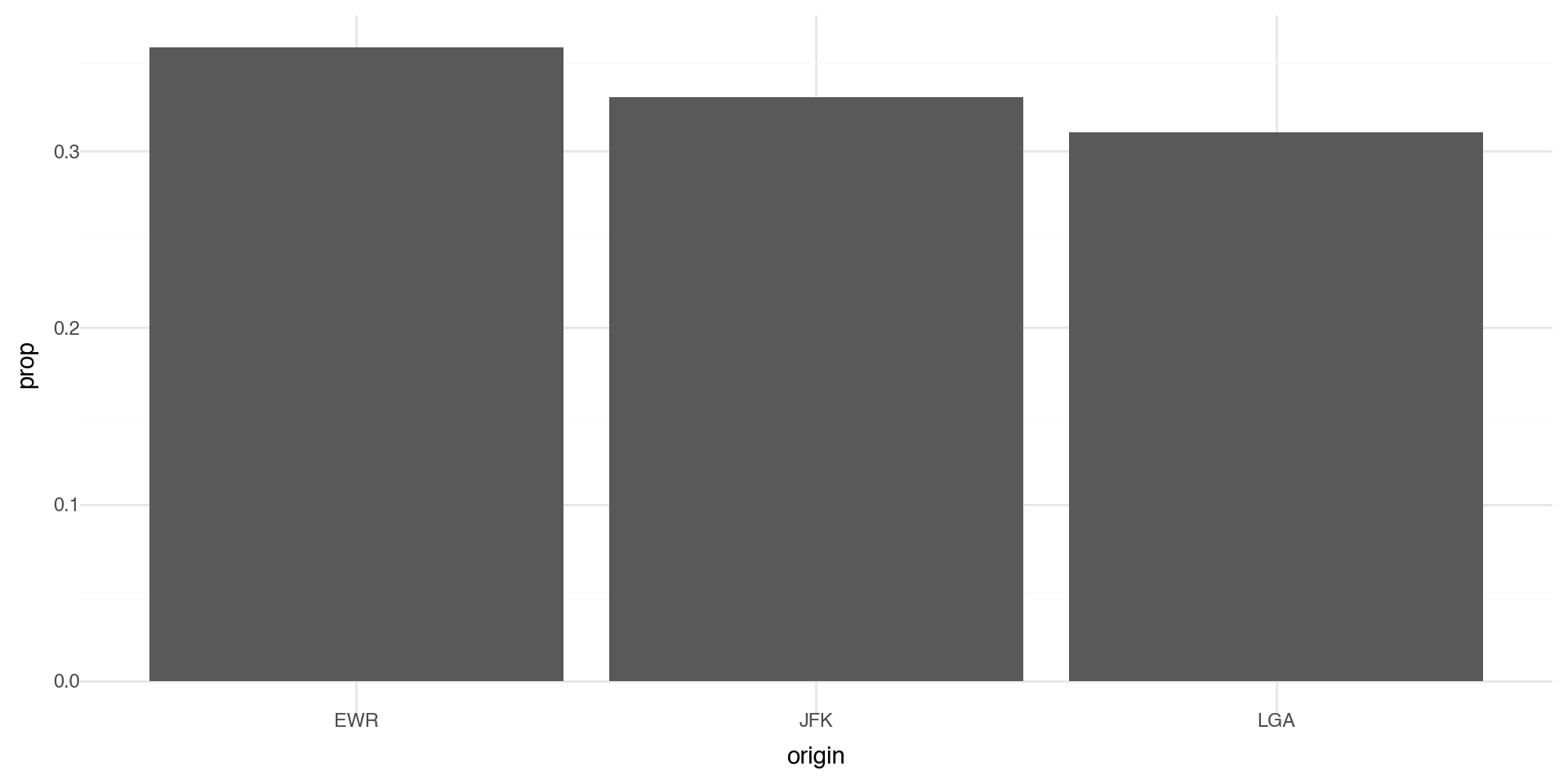
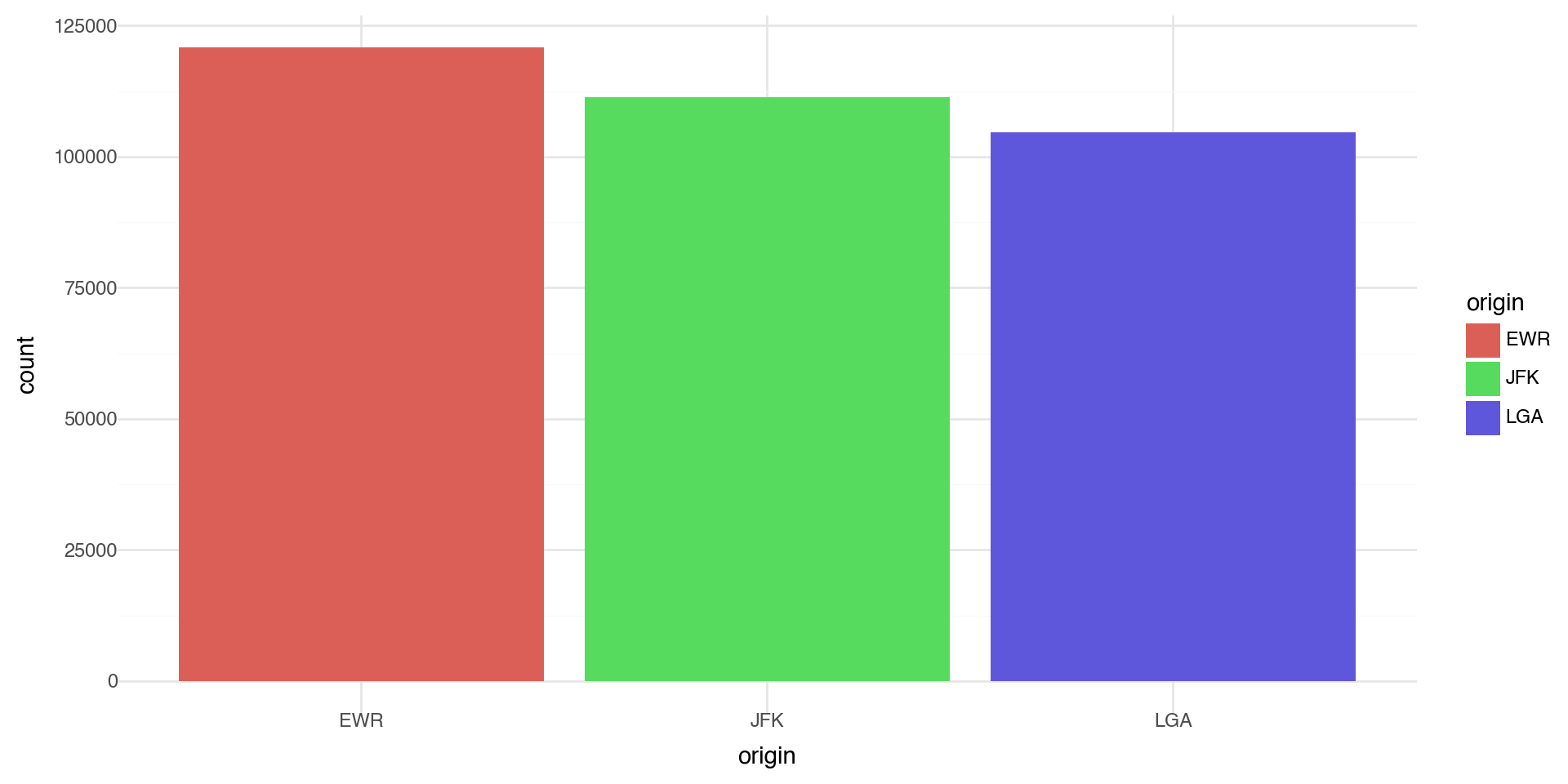
Let’s make a bar chart of the number of flights at each origin airport in 2013. The algorithm uses a built-in statistical transformation, called a “stat”, to calculate the counts.
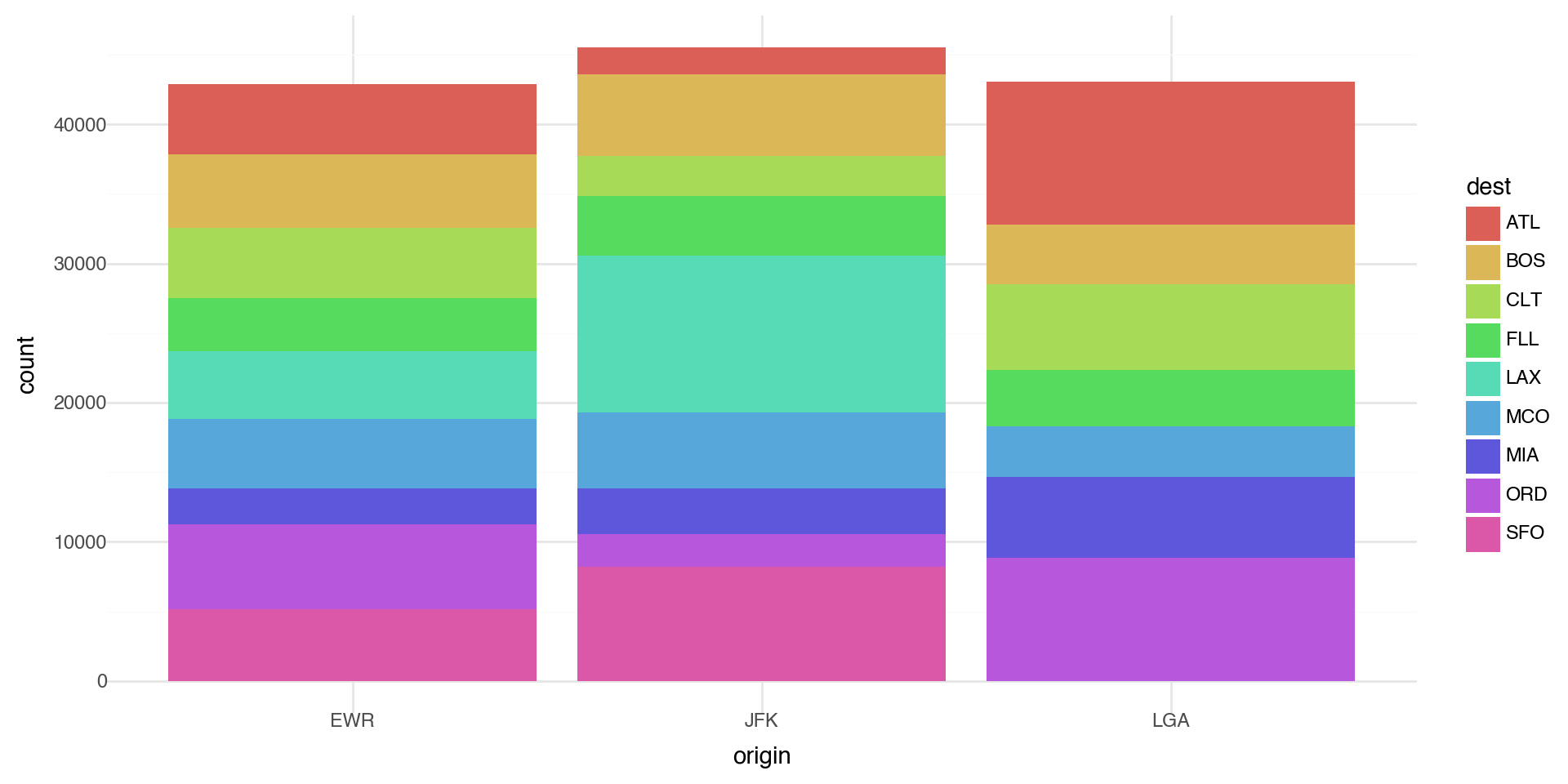
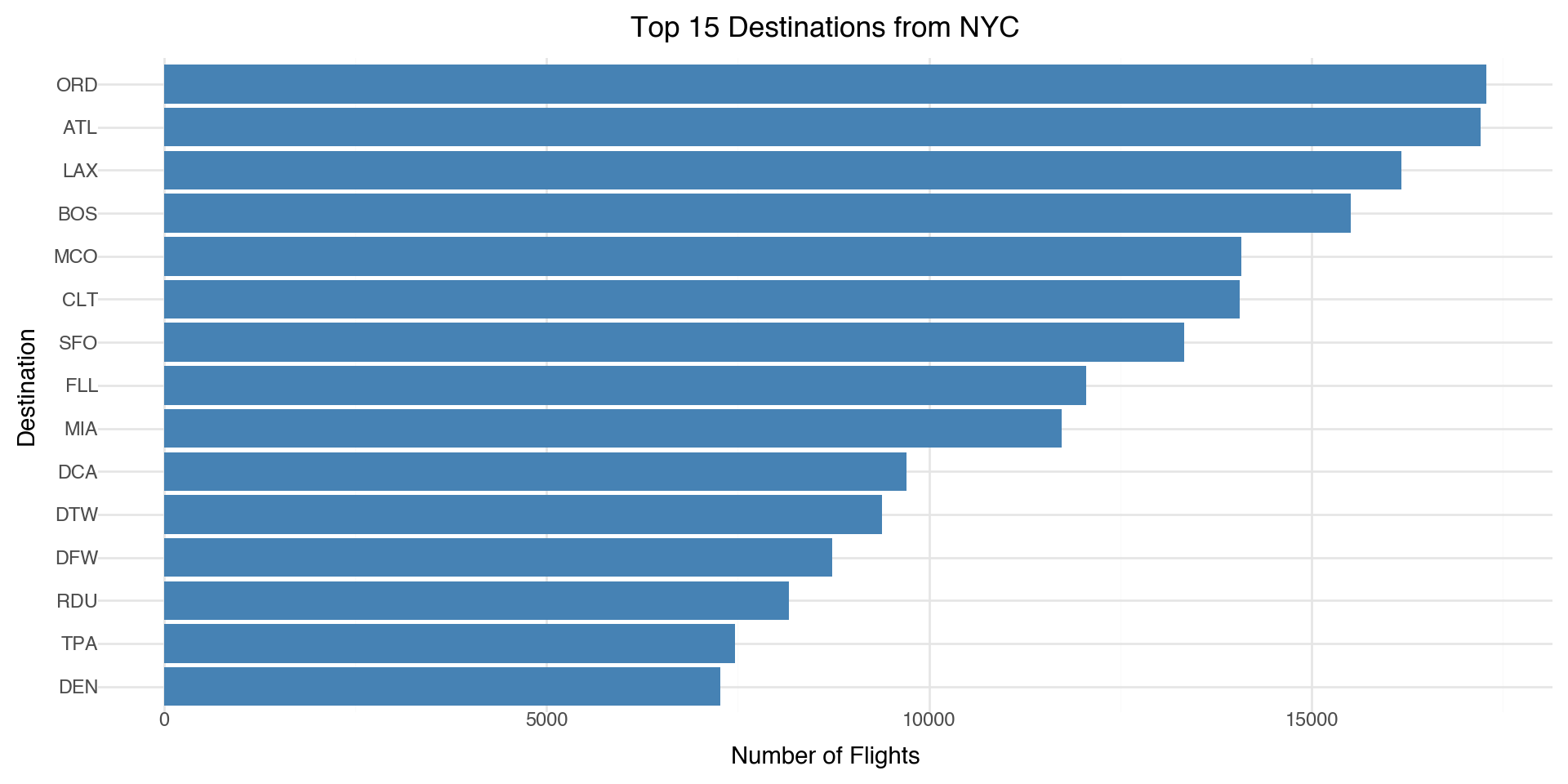
More interestingly, you can fill by another variable. Let’s first subset our data to look at the destination airports with a lot of flights (more than 10,000 flights)
You might want to draw greater attention to the statistical transformation in your code. For example, you might use stat_summary(), which summarizes the y values for each unique x value.
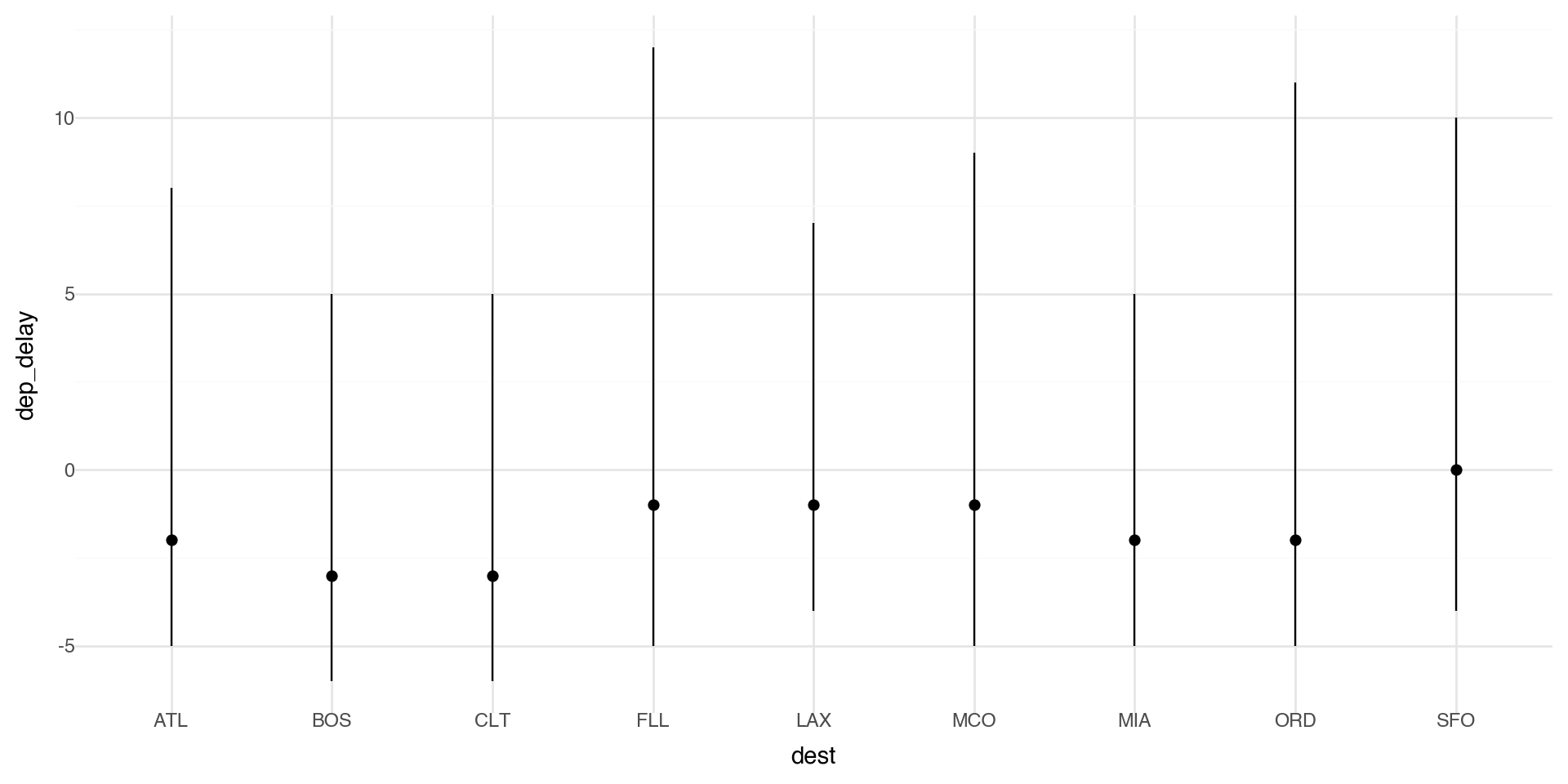
Here we plot the median delay with IQR (25th-75th quantiles) as bars.
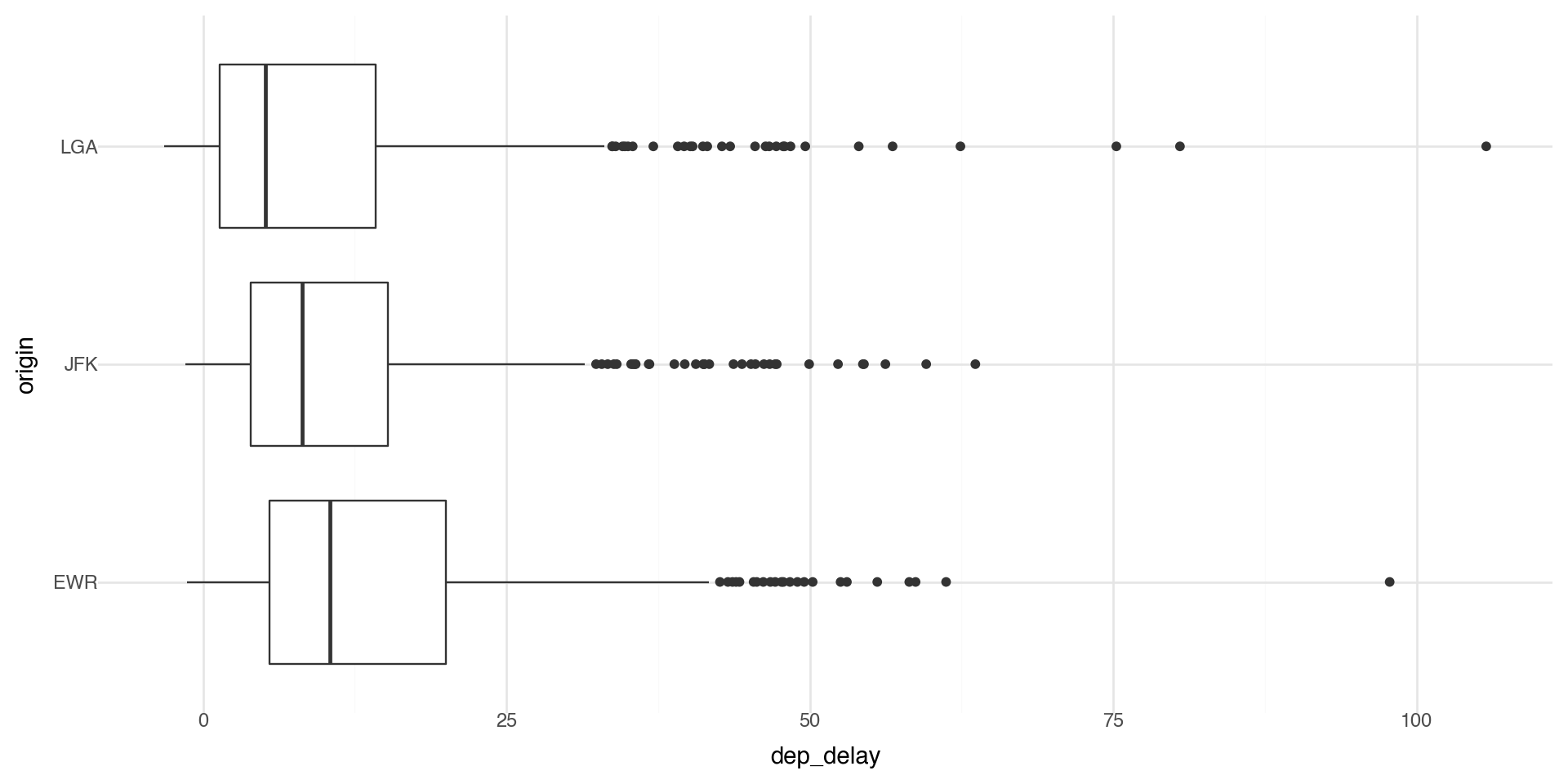
coord_flip() swaps x and y after the plot is built. Great for boxplots/bar charts to make labels readable.
coord_cartesian(xlim=..., ylim=...) zooms without dropping data (unlike hard limits on scales).
coord_fixed(ratio=1) forces equal aspect ratio (useful for geometry or maps).
Where it gets tricky
Stats + coords interactions: some geoms/stats compute first, then coords transform. Most of the time that’s fine, but it can surprise you when you expect “compute in the new coordinate system.”
Limits behavior:
scale_*_continuous(limits=...) can drop data before statistics are computed.
coord_cartesian(...) usually keeps the data and just zooms the view.
Non-Cartesian coords (if you use them): e.g., coord_polar() changes the whole geometry, so not every plot makes sense there.
Color ramps
If you add a continuous variable in your color aesthetic, it will create a color ramp. Here we apply color with the variable temp.
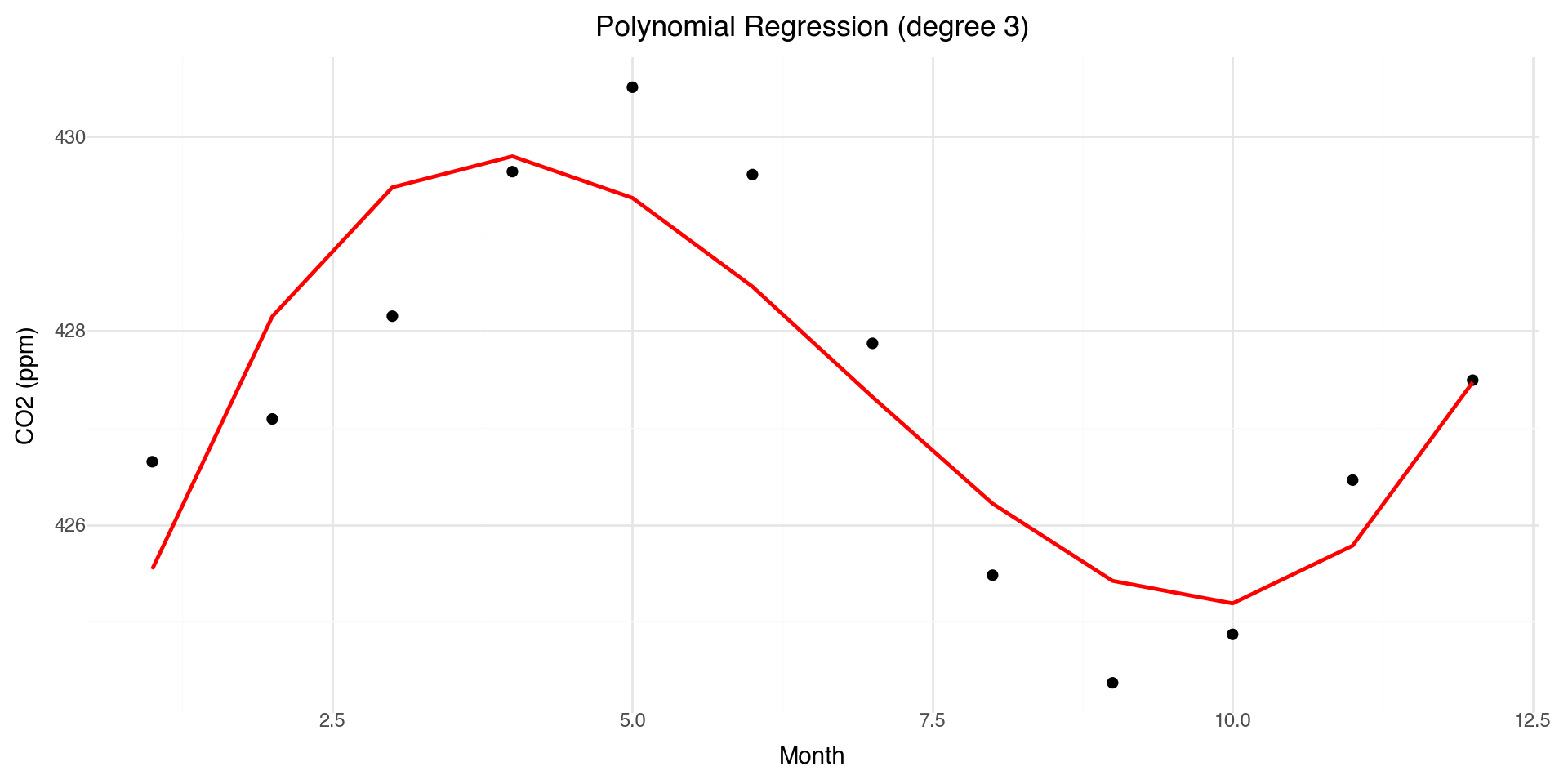
Goal: estimate a smooth function \(f(x)\) that captures the trend
Benefits:
Flexible, nonparametric modeling of trends
Still yields prediction errors (statistical smoothing)
Naturally extended to generalized additive models (GAMs)
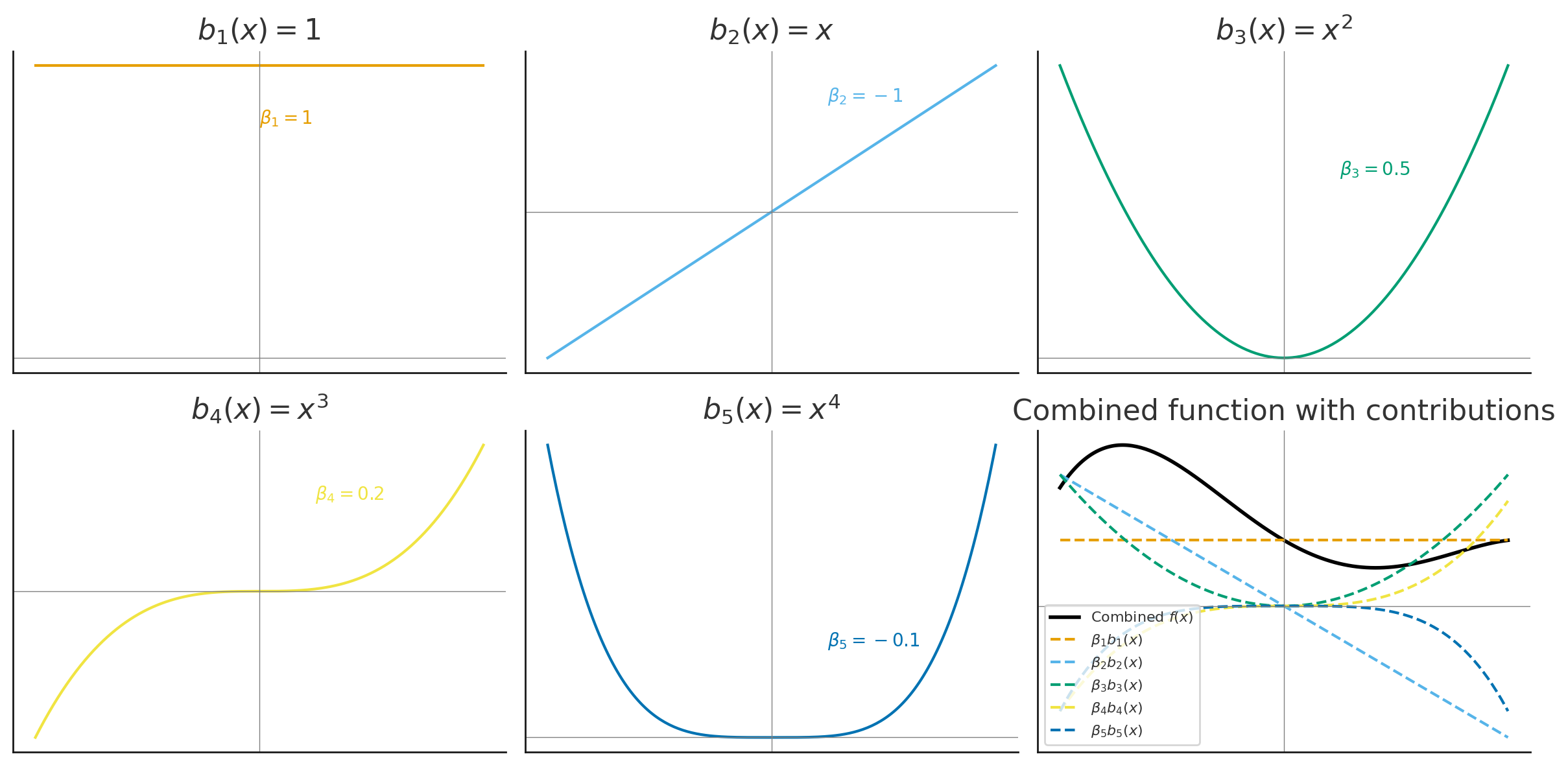
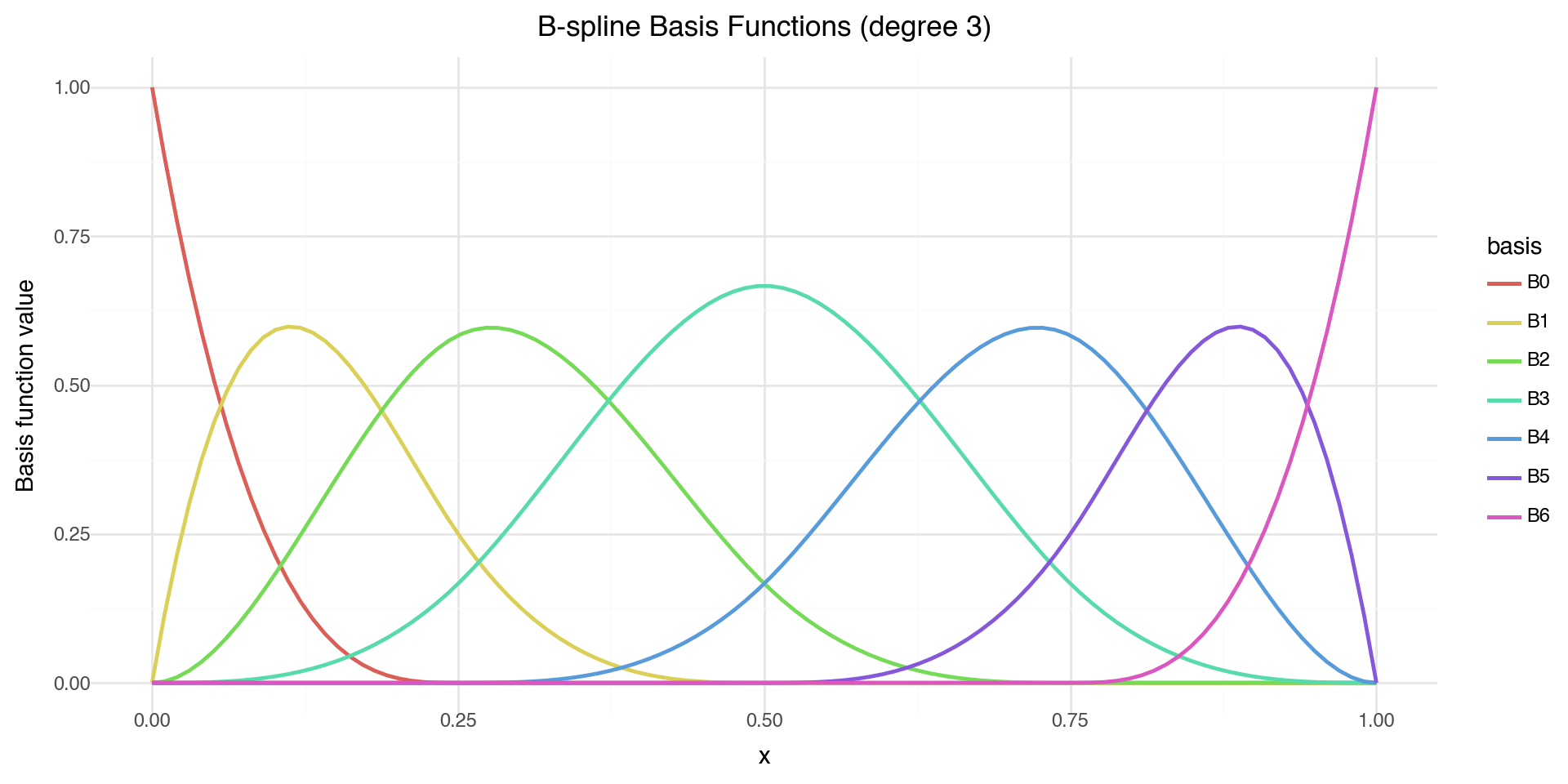
Basis Functions: Intuition
A basis is a set of simple functions \(\{b_j(x)\}\) that can be combined (with coefficients \(\beta_j\)) to approximate more complex functions \(f(x)\):
Analogy: like combining Lego blocks to build different shapes — basis functions are the blocks, coefficients \(\beta_j\) are how much of each block we use
The regression coefficients \(\beta_j\) control the contribution of each basis function
Basis Functions: Polynomial Example
Represent a complicated function \(f(x)\) as a linear combination of simpler basis functions:
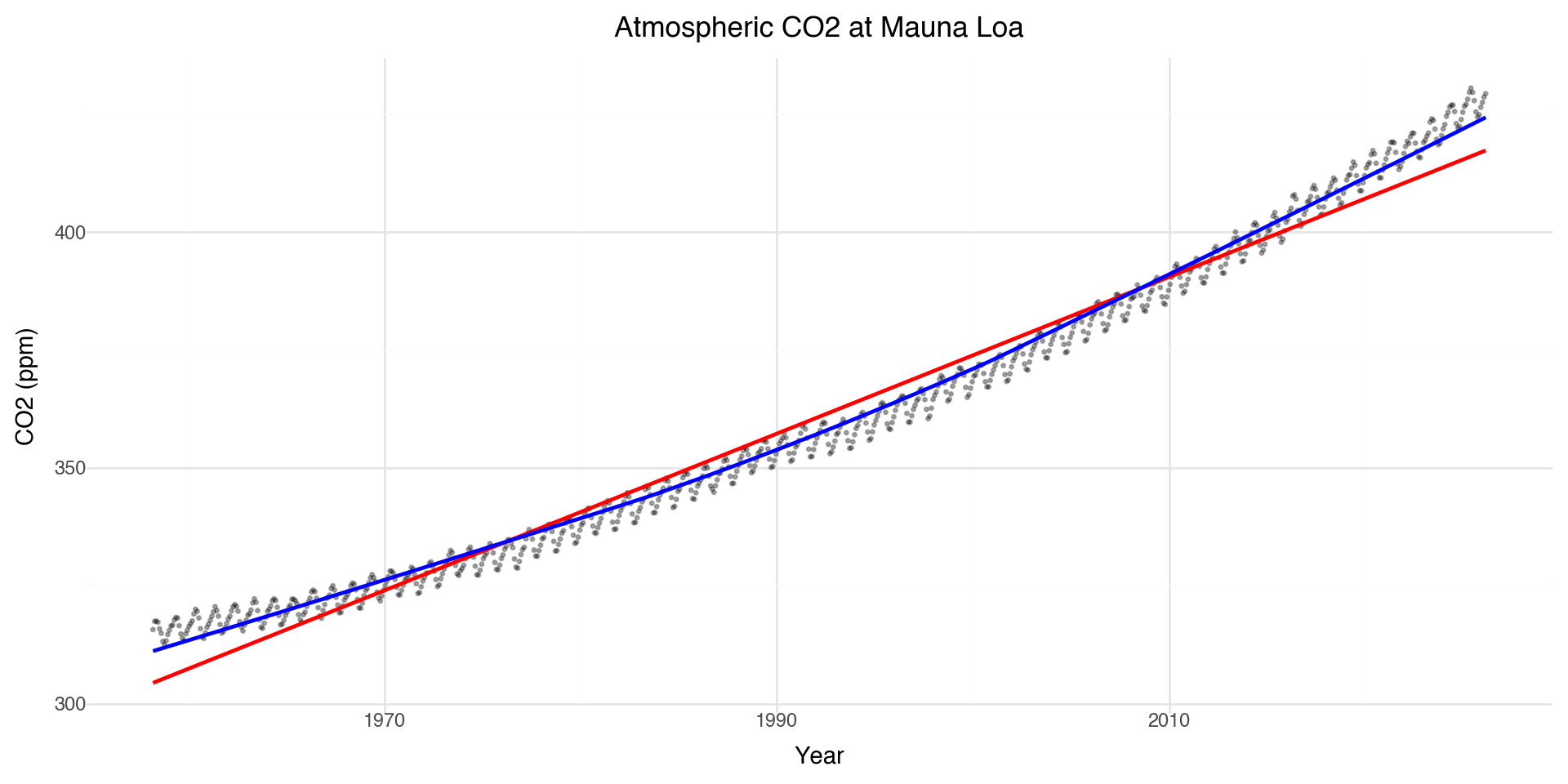
A smoothing spline fit to the CO₂ data captures both the long-term trend and seasonal cycles.
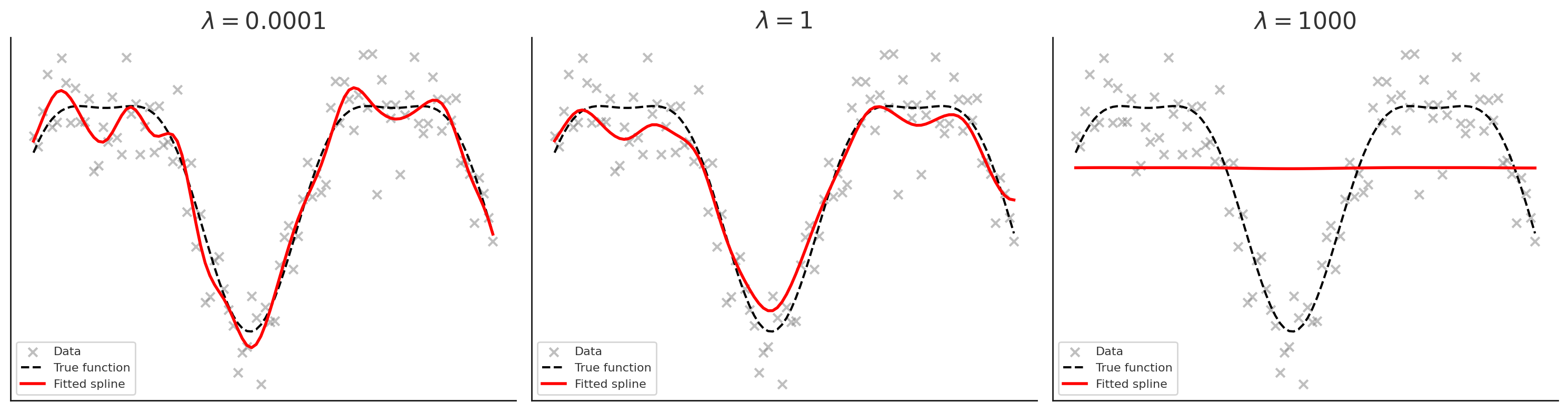
Effect of the Smoothing Parameter \(\lambda\)
Left (\(\lambda\) very small = 1e-4): spline is very wiggly, almost interpolates the noise
Middle (\(\lambda = 1\)): good balance between smoothness and fit
Right (\(\lambda\) very large = 1000): curve is almost straight (linear trend)
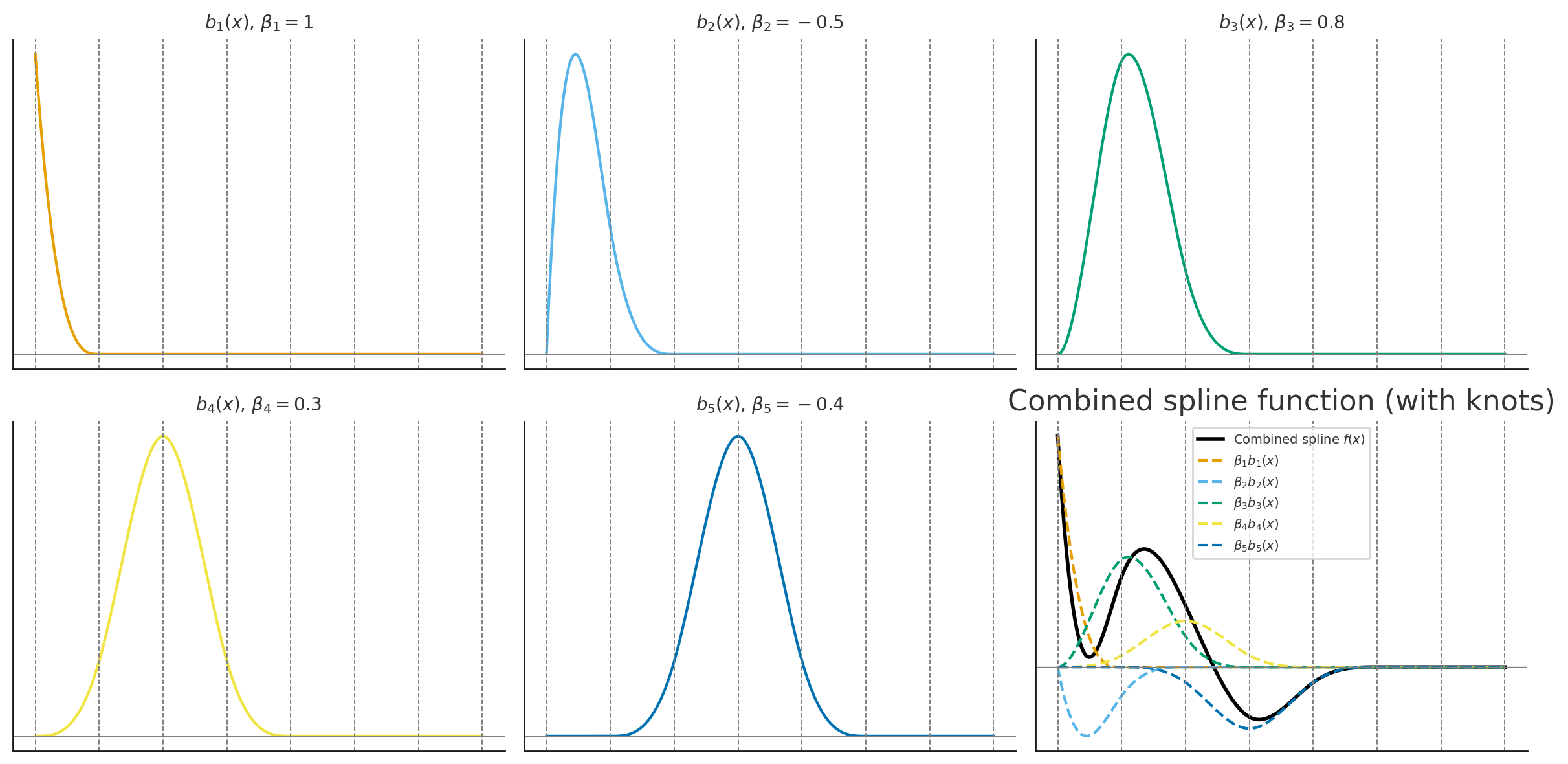
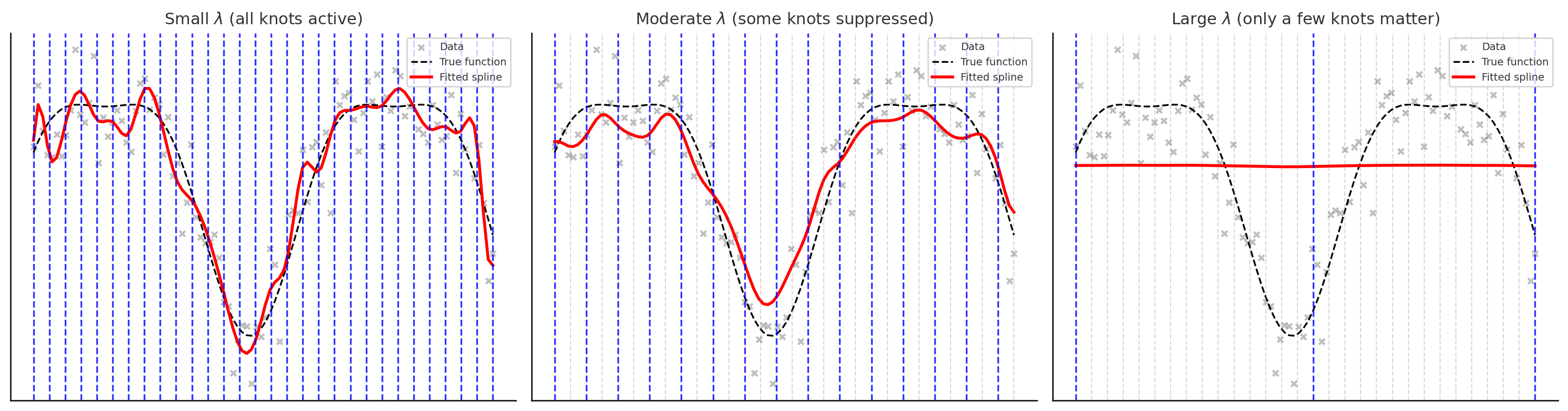
Knots vs. Penalty Parameter \(\lambda\)
In smoothing splines:
A knot is placed at each observation \(x_i\)
This gives the spline the potential to fit the data exactly
The penalty parameter \(\lambda\) controls how much we use that flexibility:
\(\lambda \to 0\): little penalty → spline interpolates the data (very wiggly)
\(\lambda \to \infty\): heavy penalty → spline approaches a straight line
Interpretation:
Knots: define the “vocabulary” of possible wiggles
\(\lambda\): decides how much of that vocabulary is actually used
Knots vs. \(\lambda\): Visualization
Small \(\lambda\): all knots are active (blue), spline wiggles to fit data closely
Moderate \(\lambda\): only some knots are active, others are suppressed (grey), leading to a smoother curve
Large \(\lambda\): only a few key knots remain active, spline is very smooth
Types of 1-D Splines: Summary
Type
Description
Cubic splines
Piecewise cubic polynomials with smooth joins at knots
Natural cubic splines
Cubic splines with boundary constraints (linear tails beyond boundary knots)
Periodic/Cyclic splines
Enforce wrap-around continuity (function and derivatives match at endpoints)
B-splines
A numerically stable basis representation for polynomial splines (local support)
Regression splines
Finite set of knots; fit spline coefficients by least squares
Smoothing/penalized splines
Knots at every point, add a roughness penalty \(\lambda\) to control fit-smoothness
Cardinal splines
Knot placement is always a certain distance apart (common in grid settings)
From Splines to GAMs
A Generalized Additive Model (GAM) extends splines to multiple predictors. It is a regression model where predictors enter through a spline. GAMs can have a combination of splines and linear terms.
LinearGAM
=============================================== ==========================================================
Distribution: NormalDist Effective DoF: 4.0838
Link Function: IdentityLink Log Likelihood: -13.6117
Number of Samples: 12 AIC: 37.3911
AICc: 47.847
GCV: 1.9142
Scale: 0.8918
Pseudo R-Squared: 0.847
==========================================================================================================
Feature Function Lambda Rank EDoF P > x Sig. Code
================================= ==================== ============ ============ ============ ============
s(0) [0.6] 10 4.1 1.45e-02 *
intercept 1 0.0 1.11e-16 ***
==========================================================================================================
Significance codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
WARNING: Fitting splines and a linear function to a feature introduces a model identifiability problem
which can cause p-values to appear significant when they are not.
WARNING: p-values calculated in this manner behave correctly for un-penalized models or models with
known smoothing parameters, but when smoothing parameters have been estimated, the p-values
are typically lower than they should be, meaning that the tests reject the null too readily.
s(0) + intercept
[ 36.58068341 38.26196477 39.94449927 41.23700237 40.90631244
38.83656747 36.99855708 37.08258697 38.46904898 40.03810926
388.35533059]
Interpreting GAM Summary
In pygam output:
s(k) represents a smooth function of predictor column k in your X matrix
f(k) represents a factor/categorical term (discrete levels)
Note on notation: In pygam, s() denotes smooth terms. This matches our mathematical notation \(s_j(x_j)\) for GAM smooth functions.
EDoF (effective degrees of freedom) tells you “what shape did the model learn?”
edf \(\approx\) 1: the term is essentially linear (heavily penalized)
edf 2–4: mild curvature
edf large: more wiggle/complexity (less penalized)
Lambda (\(\lambda\)) is the smoothing penalty — larger values = smoother curves
Interpreting GAM Coefficients
The output of gam.coef_[:] gives us the rank 10 spline basis weights (for s(0)): 36.58, 38.26, 39.94, 41.24, 40.91, 38.84, 37.00, 37.08, 38.47, 40.04
These are the beta weights \[s(x) = \sum_{j=1}^{10} \beta_j B_j(x)\]
And the intercept: 388.35533059
So the prediction is \(\hat{y} = \beta_0 + s(x)\) and the individual \(\beta_j\) values are usually not interpretable by themselves; the interpretable object is the curve \(s(x)\).
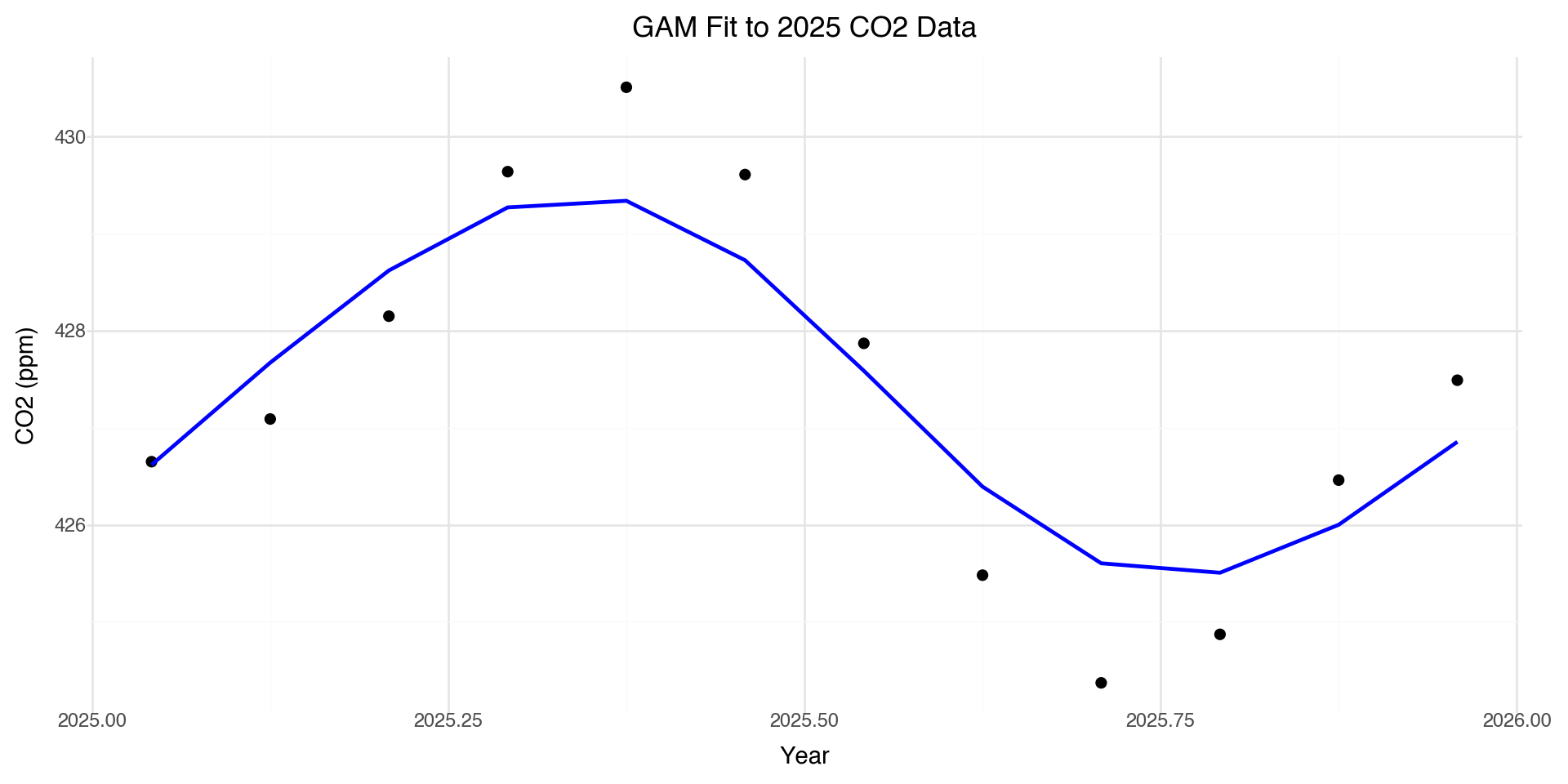
GAM Predictions
co2_2025['gam_pred'] = gam.predict(X)(ggplot(co2_2025, aes(x='decimal date')) + geom_point(aes(y='co2'), size=2) + geom_line(aes(y='gam_pred'), color='blue', size=1) + labs(x='Year', y='CO2 (ppm)', title='GAM Fit to 2025 CO2 Data') + theme_minimal())
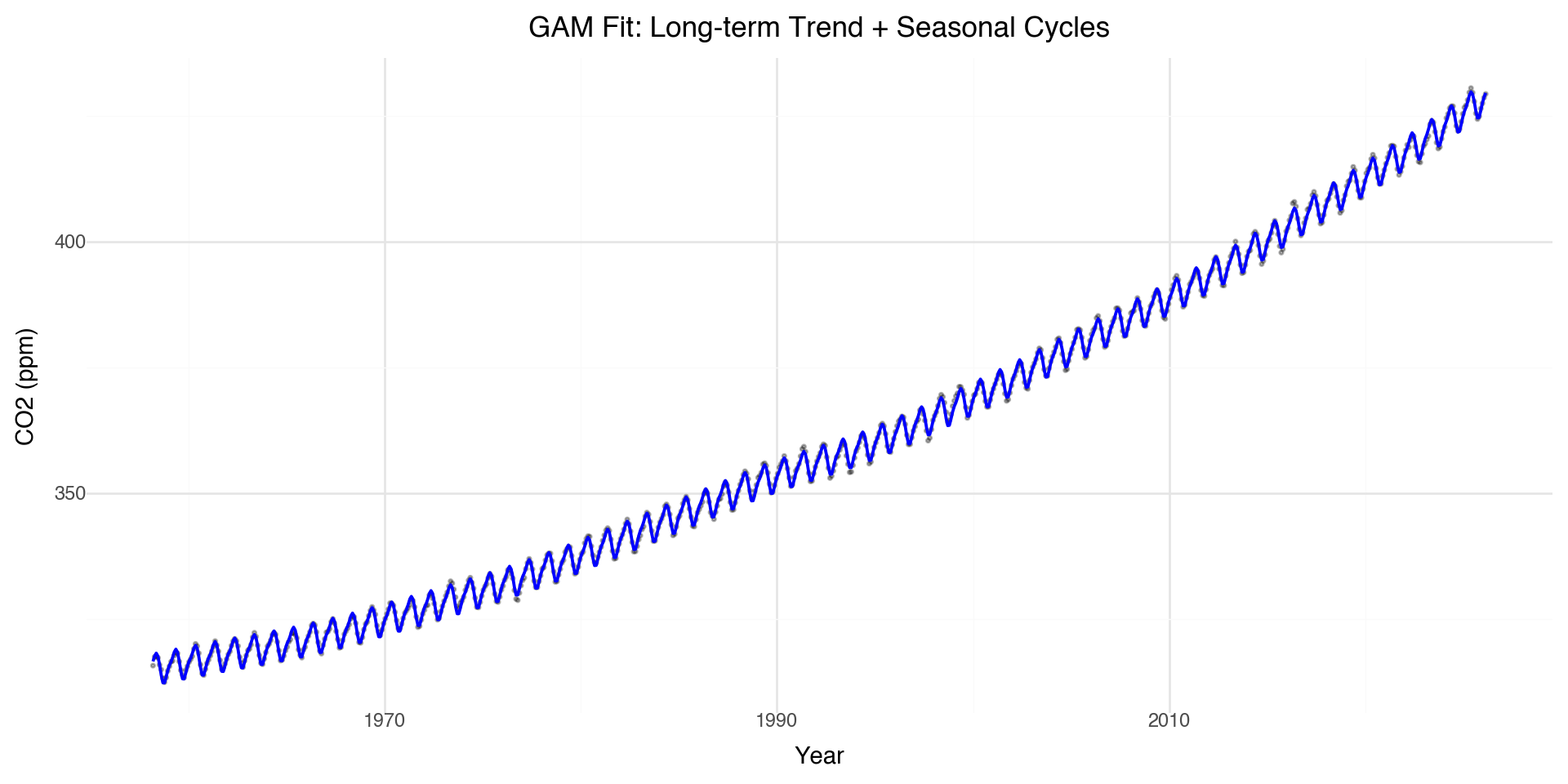
Fitting GAM to Full Dataset
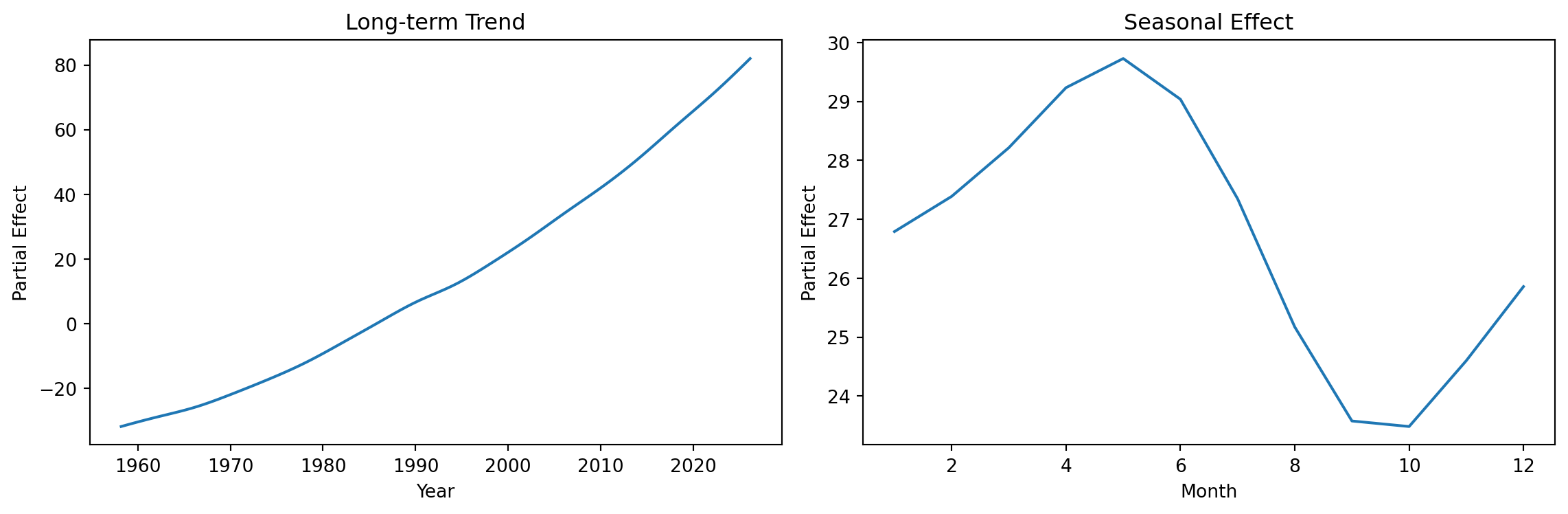
Let’s fit a GAM to capture both the long-term trend and seasonal cycles:
# Prepare full datasetX_full = co2[['decimal date', 'month']].valuesy_full = co2['co2'].values# Fit GAM with two smooth terms# s(0) for long-term trend, s(1) for seasonal (cyclic)gam_full = LinearGAM(s(0, n_splines=20) + s(1, n_splines=12)).fit(X_full, y_full)print(gam_full.summary())
LinearGAM
=============================================== ==========================================================
Distribution: NormalDist Effective DoF: 21.5794
Link Function: IdentityLink Log Likelihood: -503.623
Number of Samples: 816 AIC: 1052.4048
AICc: 1053.7486
GCV: 0.2169
Scale: 0.4545
Pseudo R-Squared: 0.9998
==========================================================================================================
Feature Function Lambda Rank EDoF P > x Sig. Code
================================= ==================== ============ ============ ============ ============
s(0) [0.6] 20 14.0 1.11e-16 ***
s(1) [0.6] 12 7.6 1.11e-16 ***
intercept 1 0.0 1.11e-16 ***
==========================================================================================================
Significance codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
WARNING: Fitting splines and a linear function to a feature introduces a model identifiability problem
which can cause p-values to appear significant when they are not.
WARNING: p-values calculated in this manner behave correctly for un-penalized models or models with
known smoothing parameters, but when smoothing parameters have been estimated, the p-values
are typically lower than they should be, meaning that the tests reject the null too readily.
None
It’s using similar smoothing techniques under the hood
The method parameter controls the smoothing approach:
'lm': Linear regression
'lowess': Local regression (default for small data)
'gam': Generalized Additive Model (R’s ggplot2)
The smooth adapts to your data automatically
# These are conceptually similar:geom_smooth() # Automatic smoothinggeom_smooth(method='lowess') # Local regression# In R: geom_smooth(method='gam') # GAM smoothing
Key GAM Concepts
Concept
Description
Spline
Piecewise polynomial with smooth connections
Knots
Points where polynomial pieces connect
Basis functions\(b_j(x)\)
Building blocks combined to form the smooth
Penalization (\(\lambda\))
Controls wiggliness, prevents overfitting
EDF
Effective degrees of freedom (complexity measure)
Notation convention:
\(f(x) = \sum_j \beta_j b_j(x)\): a spline (smooth function built from basis functions)
\(s_j(x_j)\): smooth term for predictor \(x_j\) in a GAM
When to Use GAMs
GAMs are useful when:
You expect non-linear relationships but don’t know the exact form
You want interpretable models (can visualize each smooth)
You have enough data to estimate smooth functions reliably
You want to capture seasonal patterns or trends
Cautions:
GAMs can overfit with too many knots
Higher EDF = more complex model = potential overfitting



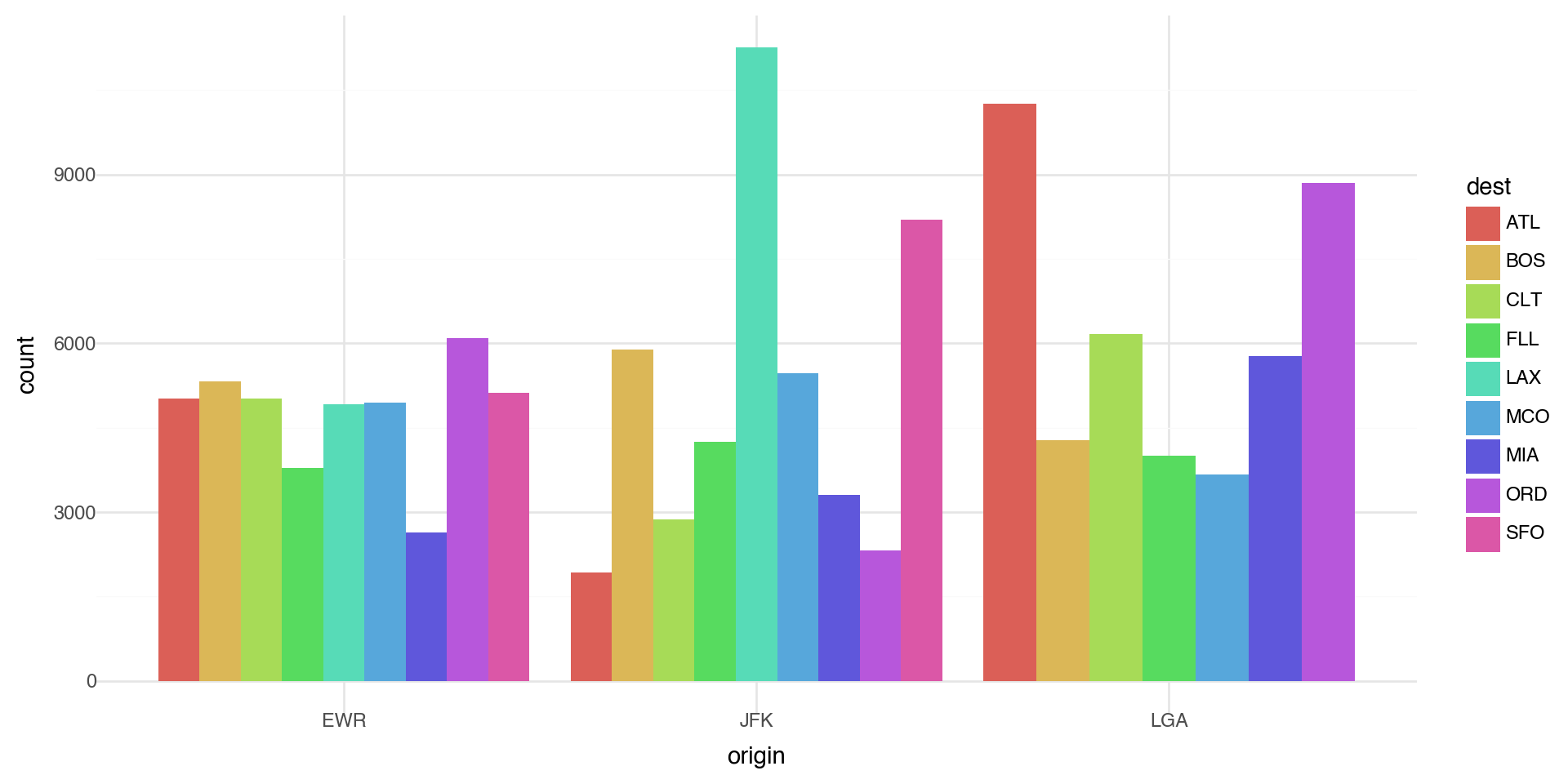

{kind=link}
{kind=link}